The idea of isolation is that we want our database to be able to process several transactions at the same time (otherwise it would be terribly slow), but we don’t want to have to worry about concurrency (because it’s terribly complicated).
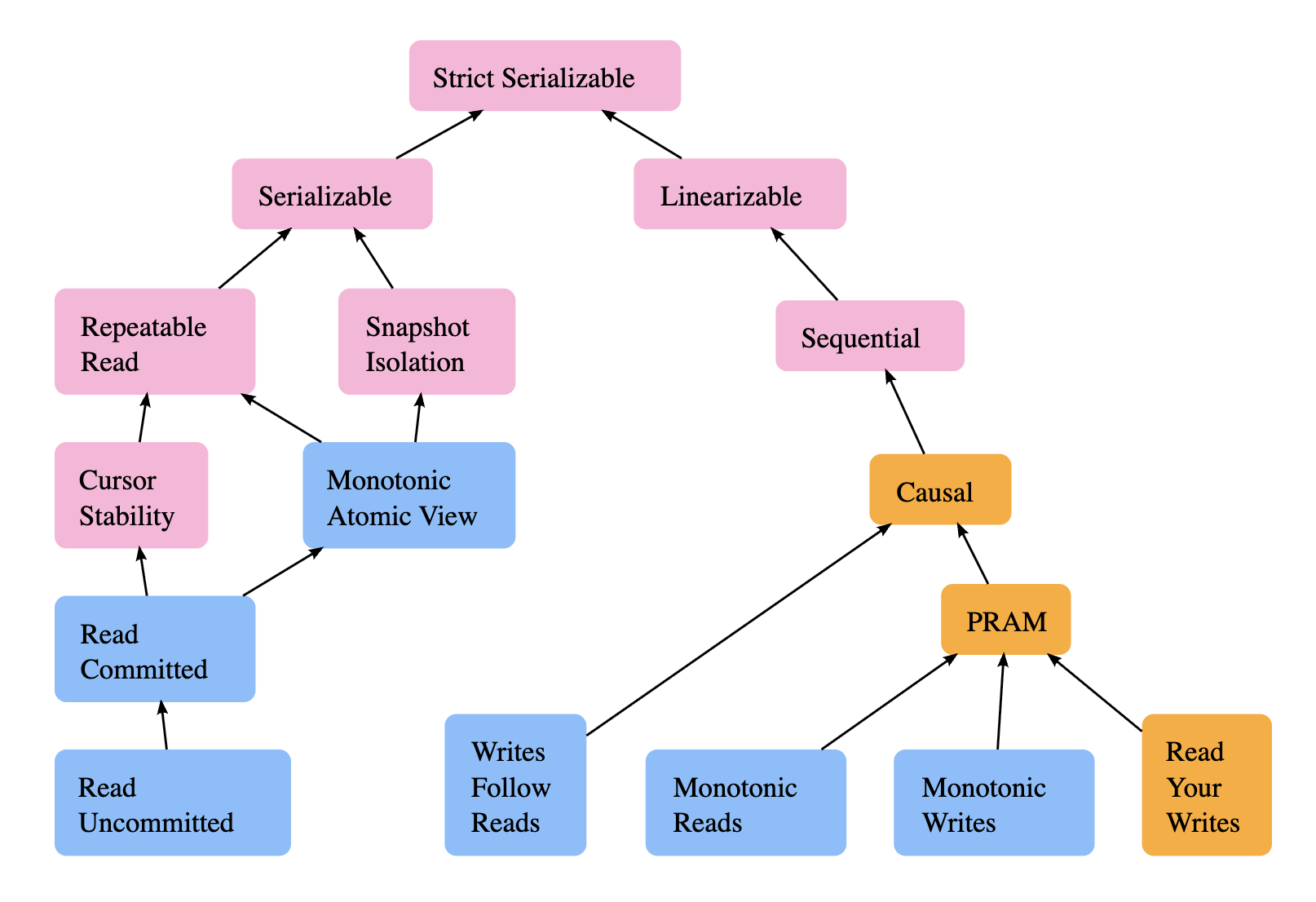
Database Transaction Isolation Levels
In increasing levels of strength of isolation.
Read Uncommitted
Transactions can read data that other transactions have modified but not yet committed.
Allows “dirty reads”: you might read data that gets rolled back.
Read Committed
Transactions only see data that has been committed by other transactions
Allows “non-repeatable reads”: same query can return different results within a transaction
Cursor Stability
Transactions can have multiple cursors which ‘lock’ access to a particular object for the duration of the transaction or until the cursor is released
This prevents lost updates, where transaction T1 reads, modifies, and writes back an object x, but a different transaction T2 transaction also updates x after T1 read x causing T2’s update to be effectively lost
Monotonic Atomic View
Prevents transactions from observing partial transaction effects. It expresses the atomic constraint from ACID that all or none of a transaction’s effects should take place
Repeatable Read
Once you read data in a transaction, subsequent reads of the same data (same rows) return the same result, even if other transactions modify it
Allows “phantom reads”: same query in a transaction can return new rows
Snapshot Isolation
Each transaction sees a consistent snapshot of the database from when it started
Allows “write skew anomalies”: two concurrent transactions read overlapping data and make decisions based on what they read, but their combined writes create an inconsistent state that violates business rules (e.g. two concurrent transactions try to deduct 50 from an account with 60 in it, both checking to see if there is at least 50. It is possible that both reads succeed and say that the account has more than 50 but the combined writes violate the invariant that the account has more than 0.)
Serializable
Transactions execute as if they ran one after another
Consistency Models
Read your writes
If a process writes then the same process subsequently reads, the read must observe the writes effects.
Monotonic writes
Write operations from a single process are observed by all processes in the same order that the process issued them.
Monotonic reads
Once a process reads a particular version of data, all subsequent reads by that same process will return either the same version or a newer version.
PRAM
Short for Pipeline Random Access Memory. PRAM preserves the program order for each individual process, but makes no guarantees about how operations from different processes are ordered relative to each other.
e.g. if A does writes W1 -> W2 and Process B does writes W3 -> W4, PRAM guarantees:
- All processes see W1 before W2
- All processes see W3 before W4
- But W1 and W3 can be seen in any relative order (
W1 -> W3orW3 -> W1)
Strictly equivalent to the combination of the above Read your writes, Monotonic reads and Monotonic writes
Writes follow reads
If a process reads a value and then performs a write, that write is guaranteed to take place on a system state that includes or comes after the read.
It is a stronger property that is a property about the dependencies across dependencies, unlike Monotonic reads and Monotonic writes.
Causal Consistency
Causally-related operations should appear in the same order on all processes though processes may disagree about the order of causally independent operations.
See also: causal
Real-time Causal Consistency
Adds the constraint to Causal Consistency that if operation X completes before operation Y starts in real-time, then Y cannot precede X in the causal order.
For example:
- Node A: Operation X finishes at
t=100mswith a vector clock<1,0> - Node B: Operation Y starts at
t=200ms, with a vector clock<0,1>
The formal real-time constraint (CC3) says that Y cannot have happened before X.
From the vector clocks:
<1,0>vs<0,1>: These are concurrent (incomparable) as<1,0> < <0,1>nor<0,1> < <1,0>, so neitherX ≺ YnorY ≺ X
Sequential Consistency
Sequential consistency implies that operations appear to take place in some total order, and that that order is consistent with the order of operations on each individual process.
This is stronger than causal consistency because it requires agreement on total order for all operations, not just causally-related ones.
Note that this can cause orderings that violate the ordering as they appear in ‘real time’. In the following example, t values represent real-time (wall-clock time):
P1: Write(x,1) [t=1-3]
P2: Write(x,2) [t=5-7]
P3: Read(x) [t=9]
Sequential consistency can order operations as P2, P1, P3 -> 1 even though in real-time P1 finished (t=3) before P2 started (t=5)
Linearizable
Every operation appears to take place atomically, in some order, consistent with the real-time ordering of those operations. This means that in the example given in Sequential Consistency, the observed order on all processes must be P1, P2, P3 -> 2
Strict serializable
Strict/Strong Serializability is Serializable + Linearizable
Operations (usually termed “transactions”) can involve several primitive operations performed in order. Strict serializability guarantees that operations take place atomically: a transaction’s sub-operations do not appear to interleave with sub-operations from other transactions.