A neural radiance field (NeRF) is a fully-connected neural network that can generate novel views of complex 3D scenes, based on a partial set of 2D images.
We represent a static scene as a continuous 5D function that outputs the radiance emitted in each direction at each point in space (see: coordinate system)
The radiance function is represented as a 4D function, with volume density value (opacity, represented as ) and a view-dependent RGB colour.
We train a simple MLP to map from position and direction to radiance. We also encourage the representation to be multiview consistent by restricting the network to predict the volume density as a function only of the location. That is:
- We train an MLP on the input 3D coordinate with 8 fully connected layers (with 256 channels per layer) to output and a 256 dimensional feature vector
- This feature vector is then concatenated with the camera ray’s viewing direction and is passed to one additional fully-connected layer (with 128 channels) that output the view-dependent RGB colour
It can be seen as interpolating between the input images to render new views
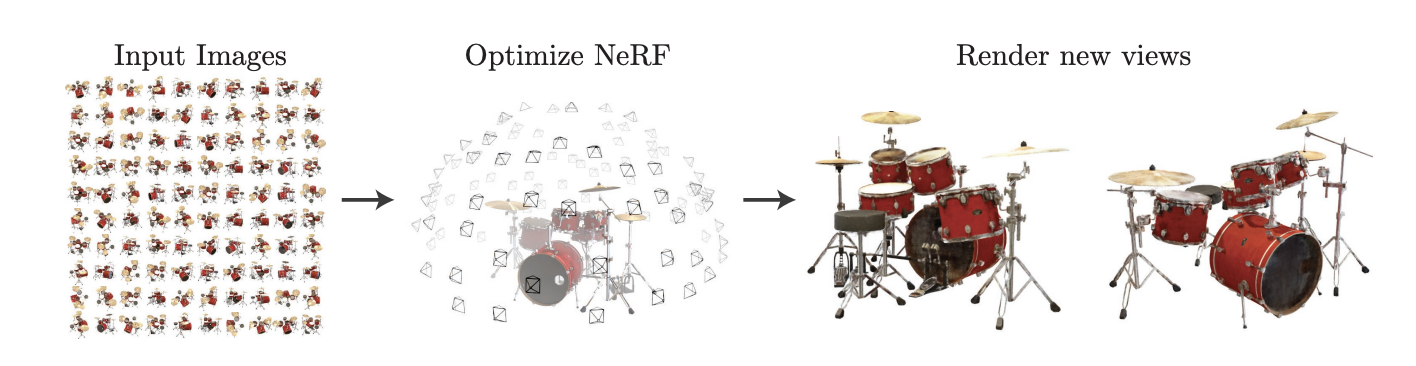
To render an image, we
- Generate a ray from the camera viewpoint to the viewing plane
- For each ray, pass the position and viewing direction as input into the neural network to produce a set of output colours and densities
- Accumulate this into a final colour and collapse it into a 2D image
Because this process is naturally differentiable, we can use supervised learning to optimize this model by minimizing the error between each observed image and the corresponding views rendered from our representation
Minimizing this error across multiple views encourages the network to predict a coherent model of the scene by assigning high volume densities and accurate colors to the locations that contain the true underlying scene content
Optimizations
- Hierarchical volume sampling
- Our rendering strategy of densely evaluating the neural radiance field network at query points along each camera ray is inefficient: free space and occluded regions that do not contribute to the rendered image are still sampled repeatedly
- Instead of just using a single network to represent the scene, we simultaneously optimize two networks: one “coarse” and one “fine”
- We first sample a set of Nc locations using stratified sampling, and evaluate the “coarse” network at these locations. Given the output of this “coarse” network, we then produce a more informed sampling of points along each ray where samples are biased towards the relevant parts of the volume
PlenOctrees
For Real-time Rendering of Neural Radiance Fields
We propose a framework that enables real-time rendering of NeRFs using plenoptic octrees, or “PlenOctrees”. Our method can render at more than 150 fps at 800x800px resolution, which is over 3000x faster than conventional NeRFs, without sacrificing quality.