- Set for one class (“important”)
- Set for the other class (“not important”)
- To predict, we look at whether is closer to +1 or -1
Least squares error may overpenalize. Only thing we care about is the sign, not how far away it is from the decision boundary.
Could we instead minimize number of classification errors? This is called the 0-1 loss function: you either get the classification wrong (1) or right (0).
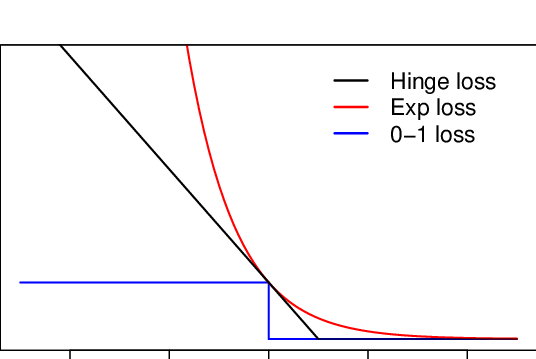
Illustration above is if . Flip for
Unfortunately, 0-1 Loss is non-convex. We can, once again, use a convex approximation which is called the Hinge loss:
See also: SVM
This is an upper bound on the 0-1 loss (as illustrated by the picture). For example, if the hinge loss is 18.3, then the number of training errors is at most 18.
Similarly, we can use the log-sum-exp trick to get the logistic loss which is convex and differentiable.
Perceptron
Only works for linearly-separable data
- Searches for a such that
- Intuition is that you search for the ledge
- Start with
- Classify each example until we reach a mistake
- Then, update to
- If a perfect classifier exists, this algorithm finds one in finite number of steps