Given data, we want to make more data that look like it
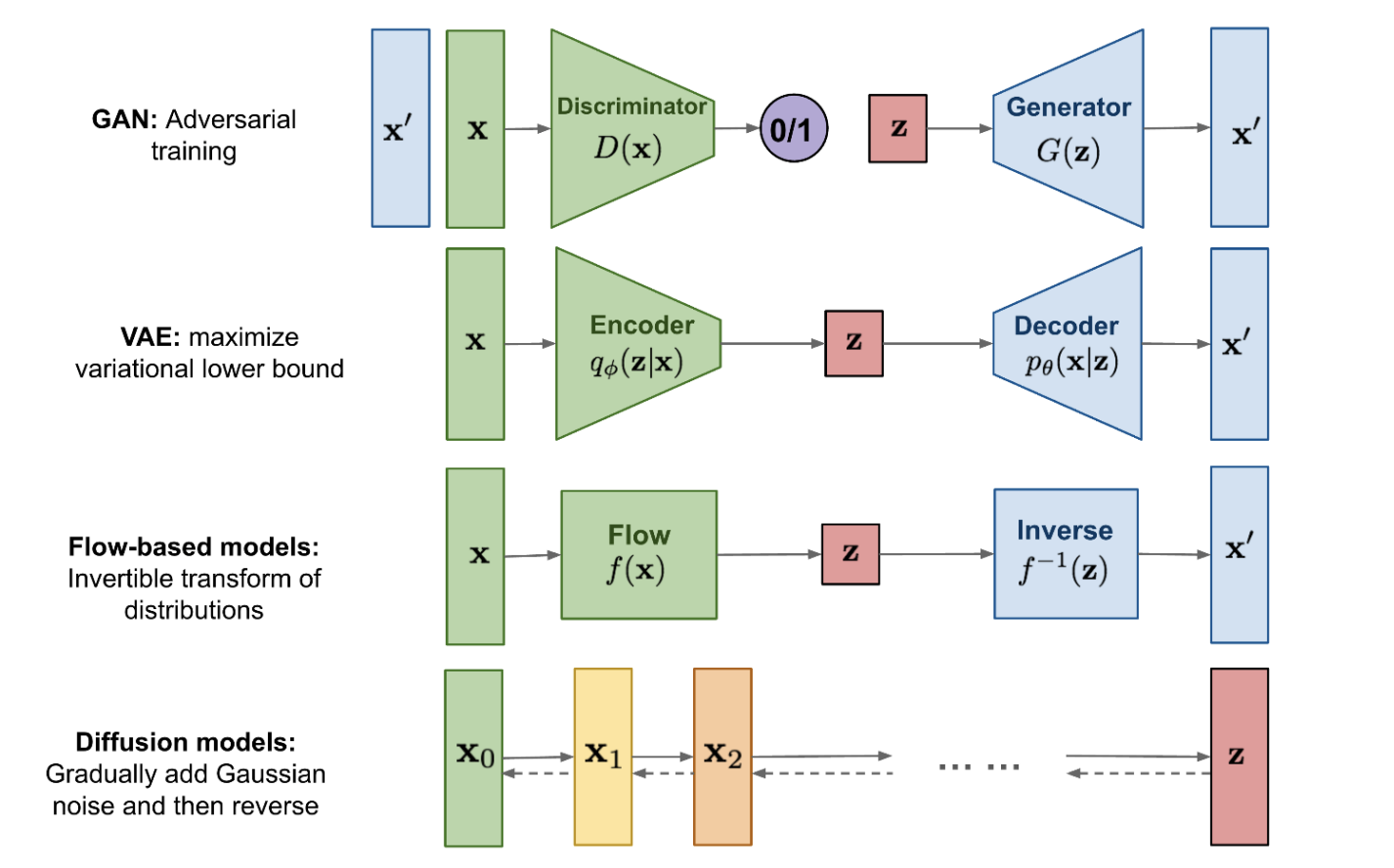
Last 10 years have seen a variety of new deep generative models:
- Variational autoencoders (VAEs)
- Generative adversarial networks (GANs)
- Normalizing flows
- Diffusion models
- Text-guided Diffusion
- A Diffusion Model starts from randomly sampled Gaussian noise so there is no way to guide this process to generate specific images. We can augment this process with textual embeddings
- Generate the image and text encoding of each of the image-caption pairs
- Trains to maximize the cosine similarity between image-caption pairs
- After this step is finished, the model is frozen