See also: object classification
Template Matching
Linear filtering is also known as template matching. Convolution/correlation can be thought of as comparing a template (the kernel) with each section of the image.
- Consider the filter and image section as vectors
- Applying the filter can be interpreted as computing the dot product between the filter and the local image patch
The correlation is then normalized to between -1 and 1 using cosine similarity, where 1 is the value when the filter and image region are identical. This process is essentially finding the cosine similarity between template and local image neighbourhood
Then, we can map over the image and create a correlation map. Thresholding this gives us detections.
Good:
- Robust against noise
- Relatively easy to compute Bad:
- Scaling (we can address this using scaled representations like a Gaussian image pyramid)
- Rotation
- Lighting conditions
- Sensitive to viewing direction and pose (in 3D worlds)
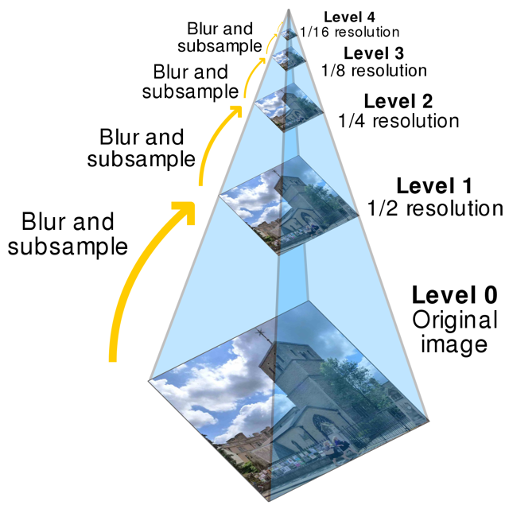
Gaussian Image Pyramid
Collection of representations of an image. Typically, each layer of the pyramid is half the width and half the height of the previous layer. In the Gaussian version, each layer is smoothed by a Gaussian then resampled to get the next layer.
Details get smoothed out (are completely lost) as we move to higher levels, only large uniform regions of colours in the original image are left.
Laplacian Pyramid
To do this, create a Gaussian pyramid and take the difference between one pyramid level and the next after smoothing but before subsampling.
At each level, retain the residuals (difference between smoothed image and normal image) instead of the blurred images themselves.
Constructing the pyramid, we repeat until min resolution reached:
- Blur
- Compute Residual
- Subsample
Reconstructing, we repeat until original resolution reached:
- Upsample
- Blur
- Sum with residual
Local Feature Detection
Moving from global template matching to local template matching (e.g.edges and corners)
As differentiation is linear and shift invariant, we can implement it as a convolution.
The discrete approximation is where is usually . This is equivalent to a convolution is a filter with the first element is and the second element is . Note that the derivatives go up for the Y direction and the right for the X direction.
We usually smooth the image prior to derivative estimation. Increased smoothing
- eliminates noise edges
- makes edges smoother and thicker
- removes fine detail
Weights of a filter for differentiation should sum to 0 as a constant image should have derivative 0.
Edge Detection
The goal here is to identify sudden changes in image brightness as this encodes the vast majority of shape information.
An edge is a location with high gradient.
Mainly caused by
- Depth discontinuity
- Surface orientation discontinuity
- Reflectance discontinuity (e.g. change in material)
- Illumination discontinuity (e.g. shadows)
As we usually smooth prior to derivative calculation and convolution is associative, we can combine both steps and use derivatives of Gaussian filters.
Sobel (Gradient Magnitude)
Let be an image. Then, we let and be estimates of the partial derivatives in the and directions, respectively. Then, the vector or is the gradient and is the gradient magnitude.
The gradient points in the direction of most rapid increase of intensity. The direction is then . The strength of the edge is then the magnitude .
Marr/Hildreth (Laplacian of Gaussian)
Design Criteria
- localization of space (find where the edge is)
- localization in frequency (identify high frequency and low frequency edges)
- rotationally invariant (rotation shouldn’t affect edges)
Find the zero-crossings (intercepts) of the Laplacian of the Gaussian. This is
Alternatively, we can say that subtracting the delta function from the Gaussian gives you an approximation of the Laplacian
Canny (Local Extrema of 1st deriv)
Design Criteria
- good detection (reduce missed edges, reduced edges where edges don’t exist)
- good localization (accurate edge detection)
- one (single) response to a given edge
Find the local extrema of a first derivative operator.
Steps
-
Apply directional derivatives of Gaussian
-
Computer gradient magnitude and gradient direction
-
Perform non-max suppression Non-max suppression allows us to suppress near-by similar detections to obtain one “true” result. In images, we select the maximum point across the width of the edge (following the direction of the gradient).
In implementations, the value at a pixel must be larger than its interpolated values at (the next pixel in the direction of the gradient) and (the previous pixel in the direction of the gradient). Interpolate as needed.
-
Linking and thresholding Trying to fix broken edge chains by linking separate edge pixels through taking the normal of the gradient and linking it if the nearest interpolated pixel is also an edge pixel. Accept all edges over low threshold that are connect to an edge over high threshold.
| Author | Approach | Detection | Localization | Single Resp | Limitations |
|---|---|---|---|---|---|
| Sobel | Gradient Magnitude Threshold | Good | Poor | Poor | Thick edges |
| Marr/Hildreth | Zero-crossings of 2nd Derivative | Good | Good | Good | Smooths Corners |
| Canny | Local extrema of 1st Derivative | Best | Good | Good |
Boundary Detection
How closely do image edges correspond to boundaries that humans perceive to be salient or significant?
One approach is using circular windows of radii at each pixel cut in half by a line that bisects the circle in half. Then, compare visual features on both sides of the cut and if the features are statistically different, then the cut line probably corresponds to a boundary.
For statistical significance:
- Compute non-parametric distribution (histogram) for left side
- Compute non-parametric distribution (histogram) for right side
- Compare two histograms, on left and right side, using statistical test
Example features include
- Raw Intensity
- Orientation Energy
- Brightness Gradient
- Color Gradient
- Texture gradient
For this implementation, we consider 8 discrete orientations () and 3 scales ()
Features
Corners are locally distinct 2D image features that (hopefully) correspond to a distinct position on a 3D object of interest in the scene.
Cannot be an edge as estimation of a location along an edge is close to impossible (the aperture problem)
Autocorrelation
Correlation of the image (distribution of pixel values) with itself. At each pixel, compute its partial derivative w.r.t. either the or the axis, .
Windows on an edge will have autocorrelation that falls of slowly in the direction of the edge but rapidly orthogonal to the edgge. Windows on a corder will have autocorrelation that falls off rapidly in all directions.
Harris Corner Detection
As a stats reminder, covariance is the direction of the correlation. The closer the covariance is to 1, the closer it is to a perfect positive correlation. -1 implies perfect negative correlation.
When drawing distrubtion, draw normals to edges going from low values (dark) to high values (white).
- Compute image gradients over small region
- Compute covariance matrix (essentially fitting a quadratic to the gradients over the small image patch )
- Computer eigenvectors and eigenvalues of the covariance matrix.
- Use threshold on eigenvalues to detect corners ( is a corner)
We can visualize the covariance matrix as an ellipse whose axis lengths are determined by the eigenvalues and orientation determined by (the rotation matrix). It tells us the dispersion of the gradients nearby.
As is symmetric, we have the covariance matrix as the ellipse equation
Where the minor axis is and the major axis is
Then, this is what the eigenvalues tell us:
- Case 1 (both and are close to zero): flat region
- Case 2 ( is much greater than ): horizontal edge
- Case 3 ( is much greater than ): vertical edge
- Case 4 ( are both rather large ): corner
To threshold, we can pick a function
- Harris & Stephens: which is equivalent to . is usually 0.4 or 0.6.
- Kanade & Tomasi:
- Nobel:
Linear Algebra Aside/Review
Given a square matrix , a scalar is called an eigenvalue of if there exists a nonzero vector that satisfies
The vector is called an eigenvector for corresponding to the eigenvalue . The eigenvalues of are obtained by solving
Keypoint Description
Scale Invariant Features (SIFT)
David Lowe
Invariant to translation, rotation, scale, and other imaging parameters. (Generally works for about ~20% change in viewpoint angle)
Advantages:
- Locality: features are local (robust to occlusion and clutter)
- Distinctiveness: individual features can be matched to a large database of objects
- Quantity: many features can be generated (even for small objects)
- Efficiency: fast (close to real-time performance)
Describes both a detector and descriptor
- Multi-scale local extrema detection
- Use difference of gradient pyramid (3 scales/octave, down-sample by a factor of 2 each octave)
- Keypoint localization
- We then remove low constrast or poorly localized keypoints. We can determine good corners by using the covariance matrix! (Threshold on magnitude of extremum, ratio of principal curvatures)
- Orientation assignment
- Create histogram of local gradient directions computed at selected scale multiplied by the gaussian kernel at the center
- Assign canonical orientation at peak of smoothed histogram (mode)
- Keypoint description (SIFT Descriptor)
- histogram of local gradient directions
- (8x(4x4)) = 128 dims
- 4x4 = 16 histograms
- 8 orientations each
- Normalized to unit length to reduce the effects of illumination change Robust to affine changes (rotation and scaling)
- histogram of local gradient directions
Histogram of Oriented Gradients (HOG)
- uses 8x8 cells and blocks which consist of 2x2 cells
- then for each cell, create a histogram of ‘unsigned’ gradients
- perform soft binning (adding to one bin also adds to neighbour bins)
- concatenate then L2 normalize
- 15x7x4x36 = 3780
’Speeded Up’ Robust Features (SURF)
- 4x4 cell grid of 5x5 cells
- each cell is represented by 4 values
- sum of all x derivatives
- sum of all y derivatives
- abs of 1
- abs of 2
- use Haar wavelets filters (simple derivative filters where all black on one side and all white on the other, weighted by gaussian)
- 4x4x4 = 64 dims
Object Recognition
- Match each keypoint to the database of keypoints To find out probability of correct match, we can compare the ratio of distance between nearest neighbour and 2nd nearest neighbour. A threshold of 0.8 provides great separation.
- identify clusters of at least 3 features that agree on an object and pose Lowe uses a generalized Hough transform
- check each cluster found by performing detailed geometric fit of affine transformation to the model
- accept/reject interpretation accordingly
Approximate Nearest Neighbour
- generally, finding nearest neighbour in high-dimensional data is linear in time (even for KD trees)
Transformations
Degrees of freedom (DOF)
- translation: 2
- rigid (euclidean): 3
- similarity: 4
- affine: 6
- projective: 8