Whenever nature seeks robustness, it resorts to networks.
The internet played a huge role in developing network theory with over a trillion documents
Power Laws and Scale-Free Networks
From the Network Science Book
A random network is a network where the degrees of connections of the nodes follow a Poisson distribution.
A scale-free network is a network where the degrees of connections of the nodes follows a power law (modelled by the Power Law , this is also where the concept of the 80/20 rule comes from). For example, roughly 80% of the web point to only 15% of the web pages.
Main difference is that power-law distributions (scale-free networks) have long tails (i.e. some nodes have lots of connections — these are called hubs).
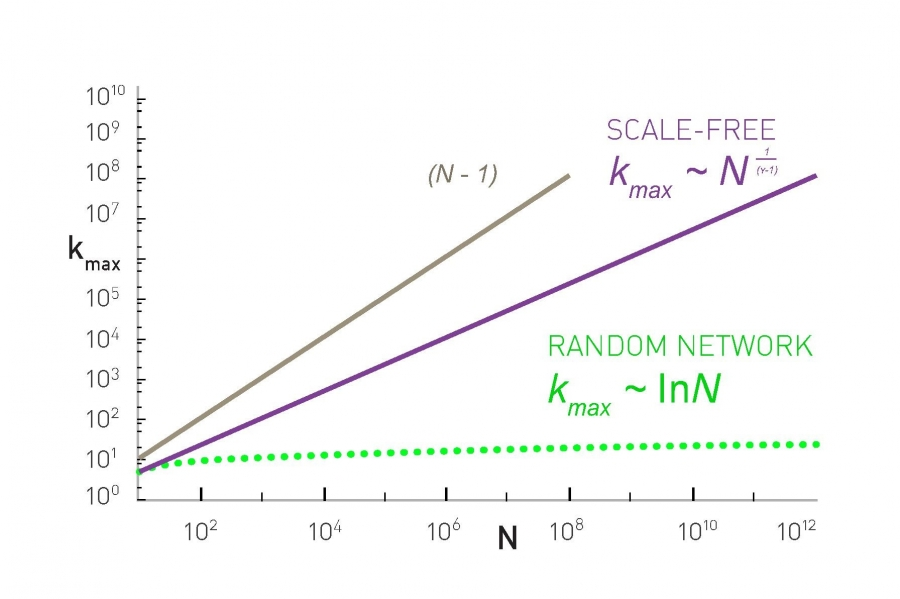
- Largest hubs in scale-free networks have degree in the order of
- Largest hubs in random networks have degree in the order of
- Largest hubs in a complete graph have degree exactly
Once hubs are present, they change the way we navigate the network. In random networks, we usually need to make many hops. On scale-free networks, however, we can reach most destinations via a single hub. Scale-free networks mean that even as the sizes may differ widely between networks, navigation time across the networks is very slow to grow (ultra-small world network).
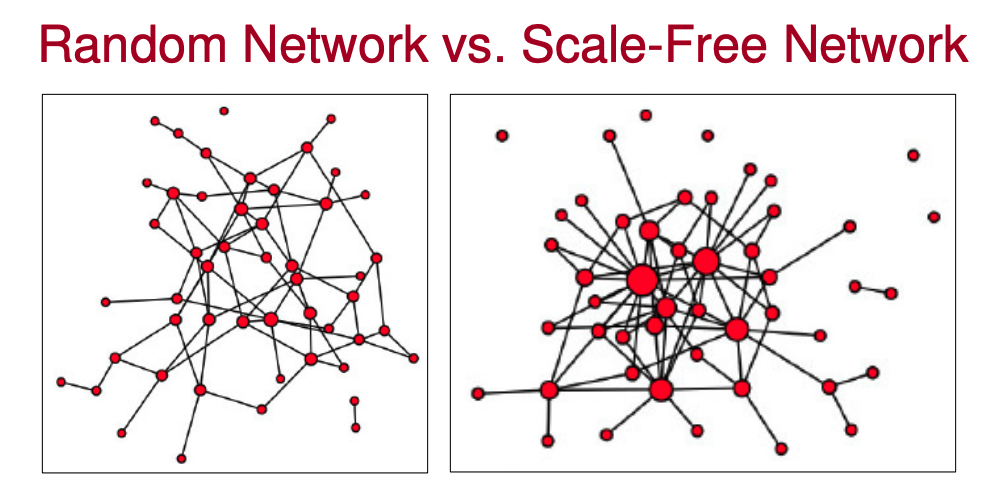
An almost universal property of most real-world networks. For example:
- Internet at the router level
- Protein-protein interaction network
- Email network
- Citation network
However, the scale free property is absent in systems that limit the number of links a node can have, effectively restricting the maximum size of the hubs.
See also: On the Power of (even a little) Centralization in Distributed Processing
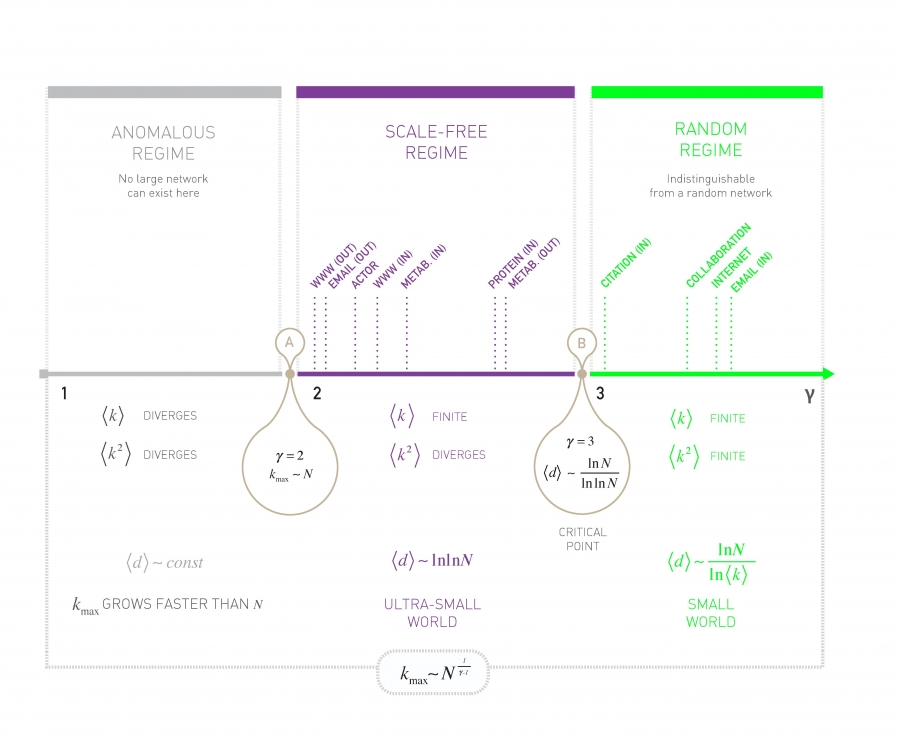
Distances in Networks
The dependence of the average distance on the system size and the degree exponent are captured by the formula
- : Hub and spoke model. so all nodes connect to a single central hub. The average path length is constant.
- : Ultra-small world model. Hubs radically reduce the path length.
- : Critical point
- : Small-world and random networks. Extremely unlikely to have large hubs, traversal time is on the order of
Network Robustness
See also: cascading failures
Percolation Theory
How many nodes do we have to delete to fragment a network into isolated components, assuming deletion is random?
We can model network breakdown as inverse percolation.
Thinking about this using the metaphor of forest fires helps to imagine what these variables mean. If we randomly ignite a tree, what fraction of the forest burns down? How long it takes the fire to burn out?
As a forest is roughly similar to a random network, the answer depends on the tree density, controlled by the parameter . For small the forest consists of many small islands of trees (), hence igniting any tree will at most burn down one of these small islands. Consequently, the fire will die out quickly. For large most trees belong to a single large cluster, hence the fire rapidly sweeps through the dense forest (). But there also exists a critical at which it takes extremely long time for the fire to end.
However, this breaks down once we consider scale-free networks. Scale-free networks observe unusual robustness to failure: we must remove all of its nodes to have likely destroyed its giant component.
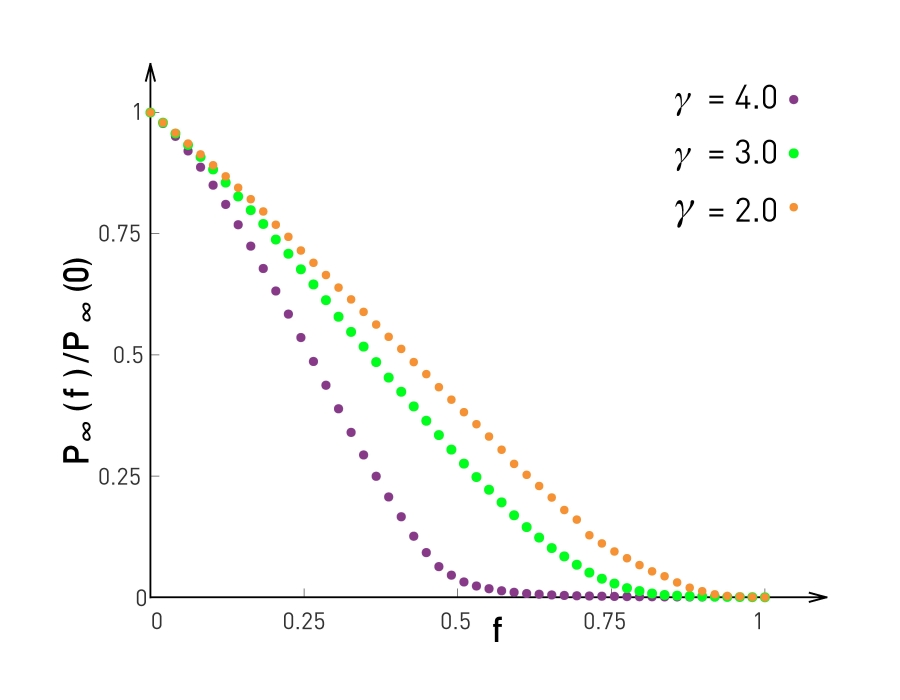
Under Attack
The removal of a small fraction of the hubs is sufficient to break a scale-free network into tiny clusters. See more on cascading failures in networks
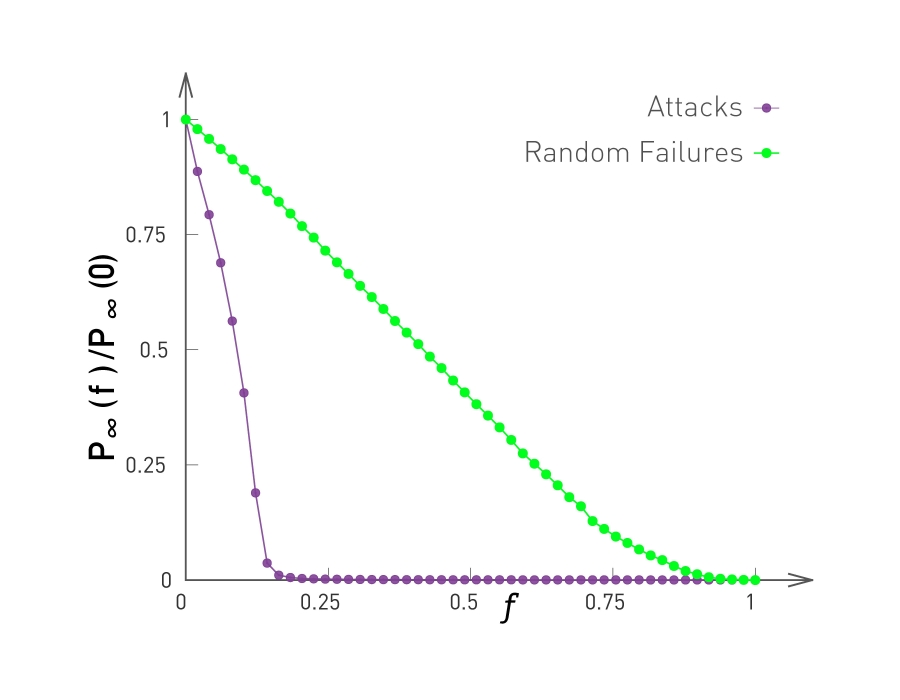 The probability that a node belongs to the largest connected component in a scale-free network under attack (purple) and under random failures (green).
The probability that a node belongs to the largest connected component in a scale-free network under attack (purple) and under random failures (green).
Knocking out even a few hubs quickly breaks down the network. Y-axis is the ratio provides the relative size of the largest connected subgraph