I think research logs tend to generally focus too much on what one did rather than what one felt. This log aspires to have a healthy mix of both.
April
April 29th
- Spent some time doing the Jepsen Maelstrom distributed systems challenges in Rust! Feel like I am slowly getting better at going from idea to working code in the language
- Going through the Causal Islands talks
April 11th
- Various notes on Operational Transform, bitemporal, incremental view maintenance, Three Legged Stool
- File system CRDTs
March
March 19th
- More notes on privacy and what a pluralistic interpretation of ‘public’ means
- Noticing some common themes between a lot of papers I’m reading lately
- Antimatter/inverse operations for undo and/or time-travel mechanisms
- Snapshotting to bound the time complexity of rewind
March 18th
- Elm time-travel debugging
- Gives me very similar vibes to how Braid does their rewind mechanism
- Elm programs may have state, even though all functions are pure. The runtime stores this state, not your program.
- The Elm runtime combines the previous state and new inputs to make the current state.
- To avoid replaying the universe from the start, Elm uses snapshotting
- Live, Rich, and Composable: Qualities for Programming Beyond Static Text
- We hypothesize that by combining liveness, richness, and composability, programming systems can meaningfully extend the capabilities of static text without losing its characteristic expressivity.
- Liveness: providing programmers with in-depth feedback about a program’s dynamic behaviour as the program is edited.
- Normally accomplished through some sort of live/hot reload that preserves the state of the system, however this only reflects the final output of the program without revealing any information on the internal model of the program that led to that output
- Richness: allowing programmers to work with domain-specific visualizations and interactions
- [W]riting code means articulating thoughts as precisely as possible… Often these thoughts involve geometrical relationships: tables, nests of objects, graphs, etc. Furthermore, the geometry differs from problem domain to problem domain. To this day, though, programmers articulate their thoughts as linear text.
- Composability: the ability to freely combine smaller programmed artifacts into larger ones, to accomplish larger goals
- Unlike liveness and richness, this is not a quality static text lacks, which interactive programming systems strive to add to it. Rather, it is a familiar quality of static text which new programming systems must work hard to maintain.
- More notes on programming models
- CRDTs and Relational Databases (RDBs)
- Defines multisynchronous access which is composed of two modes of accessing data on edge devices:
- asynchronous mode—the user can always access (read and write) the data on the device, even when the device is off-line, and
- synchronous mode—the data on the device is kept synchronous with the data stored in the cloud, as long as the device is online
- Synchronizes tuples using causal-length set CRDT (CLSet CRDT)
- Creates a two-layer relational database system where the top layer is the Application Relation (AR) Layer and the bottom is the Conflict-free Replication Relation (CRR) Layer.
- Any violation of integrity constraint is caught at the AR layer. A local update of and refresh of are wrapped in an atomic transaction: a violation would cause the rollback of the transaction. A merge at and a refresh at is also wrapped in a transaction: a failed merge would cause some compensation updates.
- Defines multisynchronous access which is composed of two modes of accessing data on edge devices:
March 13th
- Tools for development feel important to focus on for a good DX, LiveBlocks does a great job at this
March 12th
- On time
- Incremental Maintenance of Externally Materialized Views
- Wide-area access to database servers by autonomous clients (which may or may not have local databases) is becoming more and more popular
- Define monitoring service: not only request the initial answer to a certain query but also notifications about changes in this answer over an extended period of time
- Expressed in Datalog , 3-step consensus procedure that computes view differentials
March 9th
- Thick vs Thin clients
- thin clients are terminals for a centralized computer (cloud-first, internet-first)
- thick clients are computers in their own right, that sync (local-first software)
- Readings on time
- John McCarthy, inventor of LISP on logical time
- “John started thinking about modal logics, but then realized that simply keeping histories of changes and indexing them with a “pseudo-time” when a “fact” was asserted to hold, could allow functional and logical reasoning and processing. He termed “situations” all the “facts” that held at a particular time — a kind of a “layer” that cuts through the world lines of the histories.”
- NAMOS by David Patrick Reed: versions have two component names consisting of the name of an object and a pseudo-time, the name of the system state to which the version belongs
- Synchronization is then treated as a mechanism for naming version to be read and for defining where in the sequence of versions the version resulting from some update should be placed
- John McCarthy, inventor of LISP on logical time
- How is schema evolution addressed in tuple stores?
- TODO
February
February 24th
- An economically sustainable model for local-first software from the lo-fi manifesto
- Users can use the product for free on their own device, and free users don’t cost anything (or next to nothing) to “host.”
- Only paying subscribers utilize paid server infrastructure. Meaning, every server request and megabyte of database storage has associated revenue.
- I like having technical principles like “local-first,” but I’m even more excited by what these concepts can enable in terms of building more authentic, sustainable, and personable software products online.
- The hard problem of schema migration:
- “In a traditional cloud-hosted model, you’d do some diagramming, tweak your database schema to support the new system, and then schedule some time to deploy a migration. Users wake up the next day, update the app, and find their data has already been massaged into a new shape, ready for 2.0”
- “We don’t get that in local-first world. There’s no magic spell you can utter overnight to change your app’s data across everyone’s devices. You can update your own server, but the clients who connect will still be running 1.0 when they do.”
- Oasis Builders Founding Essay
- The physical frontiers of our world are largely mapped and tamed. But the digital frontier is endless, and it’s always open to settlers seeking better ways forward. We are all free to venture forth, follow our curiosity and aliveness, direct our attention in new ways, and find the others. We are free to trust our intuition when it says “things can be so much better than this.”
- Local spaces of abundance: “Oases give us the breathing room to experience the fullness and richness of our humanity. In an oasis, we have the safety, space, and resources to begin blossoming into more fully realized versions of ourselves.”
February 15th
- Gave a talk about communal computing at the DWeb YVR node that went really well
- At first, I was really nervous that people would just dismiss what I had to say because I was so young with statements like “oh he’s so naive” or “what does he know about how the internet works”
- But really, people seemed to really resonate with the talk
- If anything, it felt like it renewed their confidence that there was still young people worried about and thinking about problems like these
February 11th
- I really like how both Matrix and Email allow for people to host separately and still interop with each other
- De-perimeterizing the walled gardens of the web
- Lots of reading about networks today…
- I feel like each of the components of this project on their own could be full-fledged companies on their own. I can easily see how I could sink my entire life into this line of work
February 10th
- How do we make a DHT that works in a sparsely connected world?
- Things to tie together (how do these pieces fit together?)
- Overlay Network Layer
- Make it easy to address each other on the open web by creating a virtual private network
- Identity and Permissions Layer
- Basically key management software
- OAuth / wallet /
did:key - User friendly interface on top of persistence and data layer which embeds the persistence and data layer
- Manage which applications have access to your data/indices
- Like most other databases, includes role/access information in the underlying persistence layer
- Persistence and Data Layer
- Make it easy to spin up personal databases
- Ingestion endpoint? Converting objects to tuples
- Namespaced subscription to remote databases
- Efficient set reconciliation
- Logically monotonic
- Merge semantics and CRDTs
- Trivial merge for fact tuples is the set union operator (maybe use Hybrid Logical Clocks here too)
- Blob storage like
gitLFS - User-managed garbage collection, mark fact as retracted to update dependent indices
- Once all index nodes have ack’d the deletion, we can actually delete it (similar to Antimatter)
- Index Layer
- Query over fact store (data layer) with materialized view maintenance
- Prolly Tree data structure
- Peers are incentivized to ‘pin’ and help index data for indices they are interested in
- Application
- Folk programming
- Enables programming ‘agents’ and crawlers (like geists)
- Reads from index layer through subscriptions
- Write to persistence layer easily
- Hosting
- Network: hosted Wireguard or Headscale
- Data: On providers of the user’s choice (also managed option)
- Identity and Permissions: self-hosted application run on a user’s devices
- Each of these maintains a shallow clone of the indexes it’s interested in
- Applications: run on user’s devices
- Communal Clusters: an organizational unit, co-owning data and compute (think : a single Mastodon server)
- Index: On providers of the user’s choice (also managed option)
- Overlay Network Layer
- I feel like there is a large common ground between
git, CRDTs and room for cross-pollination across both- Both basically focus on version control and collaboration
- However, both aren’t perfect
- The railroad metaphor for
gitis powerful but the affordances of how to manipulate it aren’t made clear to the end-user. CRDTs don’t explicitly expose version control to the end-user - CRDTs have great conflict-free merge semantics that
git(relatively) sucks at
- The railroad metaphor for
- Both are also pretty bad in terms of operation efficiency
- Found out about Ditto, I guess local-first/offline-first applications make a lot of sense for aviation LOL
February 8th
- Types, not tables: I agree! What if we had a similar format for types as a sequence of map, filter, and reduce statements?
- Fact stores with schemas as queries
- Product : Product Market Fit :: Protocol : Protocol Platform Fit
- Products derive value from benefiting end-users directly
- Protocols derive value by expanding the horizons for what can be build
- That is, the value is not reified into people build on top of it
- Thus, part of the work of the protocol is figuring out the right platforms/applications that can be built on top of it and providing the right incentives for those to exist
- I suspect this is partially why so much of web3 seems like vaporware: you necessarily need to promise things to attract people to build
- But anyone who treats a protocol like a product is bound to find it suspect
- Had a chat with Spencer and Raymond about the future of data / folk forums which was really energizing
- Everything is pub-sub
- What does a protocol level inbox/outbox system for the web look like?
- Now, directly addressing people or applications is super hard because of distributed systems, NAT, and a bunch of other nasty things
- See also: communal computing
- What if we had Docker-namespace- or val.town-style application network addressing?
- Everything is pub-sub
- Notes on Braid research
- Antimatter
- RhizomeDB (Fission renamed WebnativeDB)
February 5th
- Why continually doing matters
- People talk about ‘momentum’ when it comes to projects a lot
- I get told by people looking to do more projects/research that they think about it a lot but rarely spend much time actually doing it
- Robin Sloan captures this well:
- “When you start a creative project but don’t finish, the experience drags you down. Worst of all is when you never decisively abandon a project, instead allowing it to fade into forgetfulness. The fades add up; they become a gloomy haze that whispers, you’re not the kind of person who DOES things.”
- “When you start and finish, by contrast — and it can be a project of any scope: a 24-hour comic, a one-page short story, truly anything — it is powerful fuel that goes straight back into the tank.”
- “Unfinished work drags and depresses; finished work redoubles and accelerates.”
- Truly doing something that is creative and agentic gives you energy. It doesn’t drain it
- A* path search for DHTs? Locality mapping?
- This video explainer of Meridian is really cool too! Taking account earth curvature when working with distance estimations
- Essentially, the idea is for each node-to-node query hand-off to “zoom in” to the solution space, reducing the necessary state requirement on each node to only logarithmic of the system size
- Optimizing geographical coverage through hypervolumes
- Say you have a set of K servers in your cluster
- And a set of L servers that are candidates
- Iteratively sub out servers in K for servers in L to find the set that maximizes the hypervolume to maximize the geographical coverage
- The ring members are diverse within the enclosed space by looking at the three dimensional case, which selects the three nodes from each ring that form the largest triangle
- This of course assumes laying wires that follow the curvature of the earth. Does this assumption hold for interplanetary systems? Probably not but eh we’ll think about it when we get there
- This video explainer of Meridian is really cool too! Taking account earth curvature when working with distance estimations
- Rewind in Braid, a talk by Jonathan Blow
- Implementation options
- Deterministic Simulation; record and play back user input. However, things break and it’s not robust across revisions
- Reversible sim.
tick()and alsoreversetick(). However, this makes gameplay code really complex - Record full world state; drop frames and interpolate. However, this isn’t exact and can lead to exploits.
- 40MB rewind data gives 30-60m of recording time
- Implementation options
February 4th
- Delightful apps
- What makes an app feel delightful? Optimistic Updates, Multiplayer, and Offline-Mode
- Optimistic Updates
- “Interaction time changes how you use an application. Get fast enough, and your fingertips become your primary constraint. I think this is the key to unlocking flow”
- To do this well, we need to support undo. We need to maintain order, and we need to be able to cancel dependent mutations.
- Offline-mode
- “When we know that an app will work no matter what, we use it differently.”
- Good permissions models
- User-defined functions for whether a user can modify a resource
- Why not SQL? “The frontend’s common case is SQL’s advanced case. We shouldn’t need advanced features for common cases.”
- Facebook runs on a graph database! So does Bytedance (so all of TikTok)!
February 3rd
- In response to Spencer’s creative seeing and provocation “what does the internet look like in 5 years?”
- On developing taste
- Agentic software and how current software makes it hard for people to make their own things
January
January 30th
- Alan Kay on “Should web browsers have stuck to being document viewers”
- This led to a “sad realization” that sending a data structure to a server is a terrible idea if the degrees of freedom needed on the sending side are large.
- And eventually, this led to a “happy realization”, that sending a program to a server is a very good idea if the degrees of freedom needed on the sending side are large.
January 29th
- I hosted a session in Andy Matuschak’s unconference! It turns out a lot of people are thinking about collaborative software. It was super causal and we just chatted about ideas for 30 minutes but wow I felt so energized afterwards.
- Some ideas I found particularly insightful:
- “What is the handwriting for digital spaces? Something that passively conveys ownership for a particular unit of work” (Gus Rasch)
- “Someone just surfaced the idea of personal fonts and some other avenues are 1. color, and 2. hand-drawn image” (Spencer)
- “Imbuing digital spaces with personality feels more powerful than you might expect. Makes it easier to remember where things live because they’re “emotionally” different.” (Amelia Wattenberger)
- Effective diff interfaces: “one of the most important factors here is being able to quickly understand the difference between versions.” (Amelia Wattenberger)
- Domain-specific merge flows: “How do you enable people to manage many copies and forks of the same document and recombine? Is this going to be the same for prose and digital gardening as it will be for coding? Could we use LLMs to describe differences semantically?” (Rob Haisfield)
- “What is the handwriting for digital spaces? Something that passively conveys ownership for a particular unit of work” (Gus Rasch)
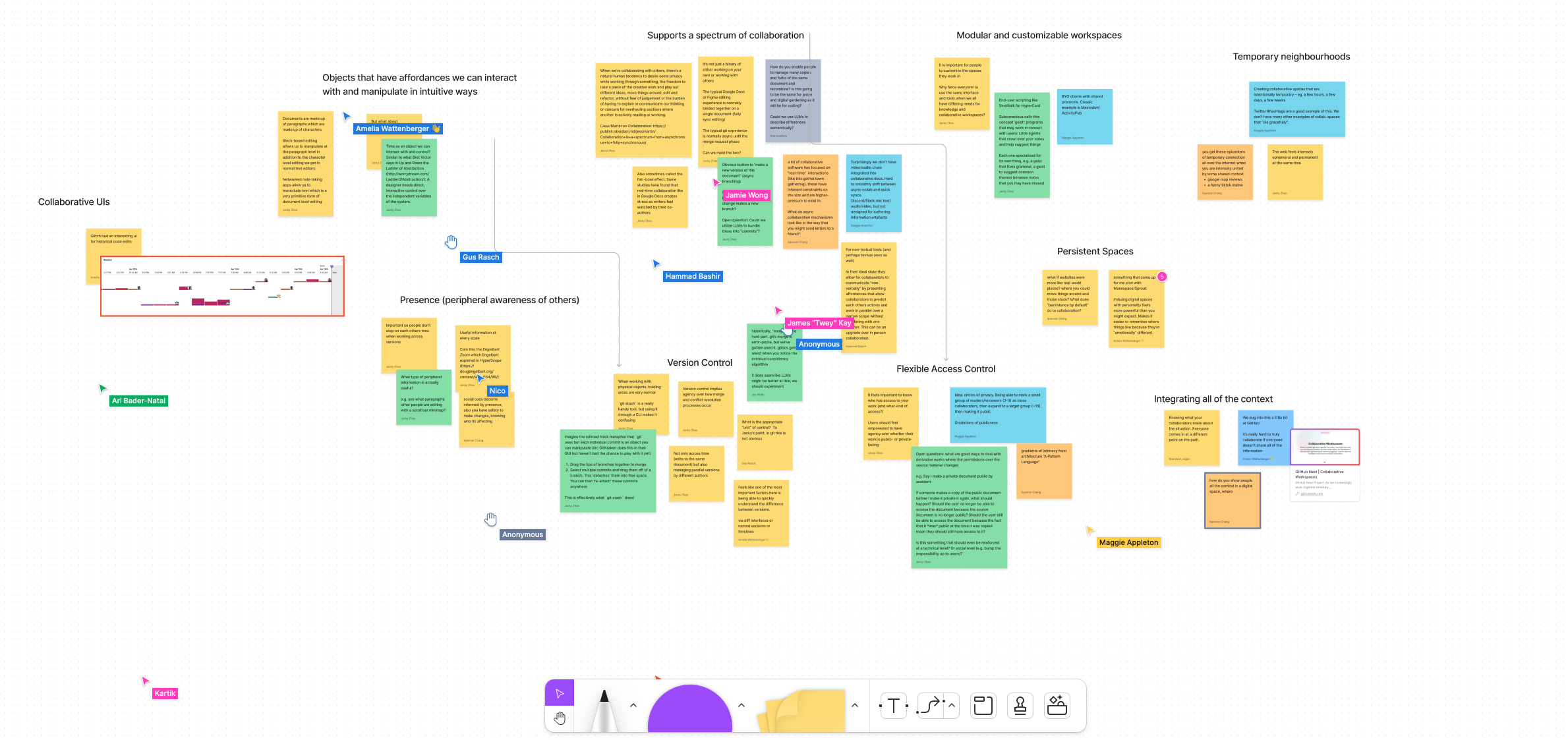
January 28th
- Started thinking about this Git for writing idea which I think will be a good vehicle for thinking about version control systems in general
- Prototype Sketch
- Question: what feels good about a collaborative medium?
- Objects that have affordances we can interact with and manipulate in intuitive ways
- Documents are made up of paragraphs which are made up of characters
- Block-based editing allows us to manipulate at the paragraph level in addition to the character level editing we get in normal text editors
- Networked note taking apps allow us to transclude text which is a very primitive form of document level editing
- But what about manipulating documents through time?
- Time as an object we can interact with and control? Similar to what Bret Victor says in Up and Down the Ladder of Abstraction: A designer needs direct, interactive control over the independent variables of the system.
- See notes below on version control
- Documents are made up of paragraphs which are made up of characters
- Supports a spectrum of collaboration
- When we’re collaborating with others, there’s a natural human tendency to desire some privacy while working through something, the freedom to take a piece of the creative work and play out different ideas, move things around, edit and refactor, without fear of judgement or the burden of having to explain or communicate our thinking or concern for overhauling sections where another is actively reading or working. (Jess Martin on Collaboration)
- Also sometimes called the fish-bowl effect. Some studies have found that real-time collaboration like in Google Docs creates stress as writers feel watched by their co-authors
- It’s not just a binary of either working on your own or working with others
- Normally binded together on a single document (fully sync editing)
- This is the typical Google Docs or Figma editing experience
- Obvious button to “make a new version of this document” (async branching)
- What if we did ‘implicit’ branching where any change makes a new branch?
- Open question: Could we utilize LLMs to bundle these into “commits”?
- Each copy has an obvious flow of “merge back into original document”
- What if we did ‘implicit’ branching where any change makes a new branch?
- Normally binded together on a single document (fully sync editing)
- Presence (peripheral awareness of others)
- Important so people don’t step on each others toes when working across versions
- Useful information at every scale
- Coin this the Engelbart Zoom which Engelbart explored in HyperScope
- TKTK: what type of peripheral information is actually useful?
- e.g. see what paragraphs other people are editing with a scroll bar minimap?
- When we’re collaborating with others, there’s a natural human tendency to desire some privacy while working through something, the freedom to take a piece of the creative work and play out different ideas, move things around, edit and refactor, without fear of judgement or the burden of having to explain or communicate our thinking or concern for overhauling sections where another is actively reading or working. (Jess Martin on Collaboration)
- Version control
- Not only across time (edits to the same document) but also managing parallel versions by different authors
- Version control implies agency over how merge and conflict resolution processes occur
- ‘Best-effort’ merge using traditional merge techniques (borrowing from CRDTs or
gitmerge strategies)
- ‘Best-effort’ merge using traditional merge techniques (borrowing from CRDTs or
- When working with physical objects, holding areas are very normal
git stashis a really handy tool, but using it through a CLI makes it confusing- Imagine the railroad track metaphor that
gituses but each individual commit is an object you can manipulate (iirc GitKraken does this in their GUI but haven’t had the chance to play with it yet)- Drag the tips of branches together to merge
- Select multiple commits and drag them off of a branch
- This ‘detaches’ them into free space
- You can then ‘re-attach’ these commits anywhere
- This is effectively what
git stashdoes
- This is effectively what
- Flexible Access Control
- It feels important to know who has access to your work (and what kind of access?)
- Users should feel empowered to have agency over whether their work is public- or private-facing
- These should also be flexible and dynamic
- Open questions: what are good ways to deal with derivative works where the permissions over the source material changes
- e.g. Say I make a private document public by accident
- If someone makes a copy of the public document before I make it private it again, what should happen? Should the user no longer be able to access the document because the source document is no longer public? Should the user still be able to access the document because the fact that it was public at the time it was copied mean they should still have access to it?
- Is this something that should even be reinforced at a technical level? Or social level (e.g. bump the responsibility up to users)?
- It feels important to know who has access to your work (and what kind of access?)
- Modular and customizable workspaces
- It is important for people to customize the spaces they work in
- Why force everyone to use the same interface and tools?
- We all have differing needs for knowledge and collaborative workspaces
- End-user scripting like Smalltalk for HyperCard
- Subconscious calls this concept ‘geist’: programs that may work in concert with users
- Little agents that crawl over your notes and help suggest things
- Each one specialized for its own thing, e.g. a geist that fixes grammar, a geist to suggest common themes between notes that you may have missed
- It is important for people to customize the spaces they work in
January 15th
- Declarative Programming over Eventually Consistent Data Stores
- “geo-distribution does not come for free; application developers have to contend with weak consistency behaviors, and the lack of abstractions to composably construct high-level replicated data types, necessitating the need for complex application logic and invariably exposing inconsistencies to the user”
January 14th
- Ladder of Abstraction
- A designer needs direct, interactive control over the independent variables of the system. We must not be slaves to real time.
- Query Guarantees in Keep CALM and CRDT On
- “The soundness of state convergence does not translate to predictable guarantees for computations that examine them. One might say that CRDTs provide Schrodinger consistency guarantees: they are guaranteed to be consistent only if they are not viewed”
- “Can we develop a query model that makes it possible to precisely define when execution on a single replica yields consistent results?”
- Querying over something monotonic would be nice but computer time is non-monotonic? What about entropy?
- “The space of monotone queries is quite large; for example, four of the five operators of relational algebra are monotone: selection, projection, union, and intersection. Only set difference is non-monotone.”
- “A pipeline composing monotone functions will always give a monotone function end-to-end, but if the pipeline contains any non-monotone function then the end-to-end-computation will be non-monotone”
- ^ this is quite similar to earlier observations about RedBlue consistency
- “With apologies, potentially-inconsistent observations are accompanied by compensating actions, which are intended to clean up any negative effects of weak consistency. By leveraging lineage tracing, a CRDT-enabled database could automatically determine when such apologies are necessary, prompting the application accordingly”
- How does this compare with netcode rollback techniques?
- Upwelling pre-print
- Presence affordance that is not intrusive? (“I’m working on the introduction today, please don’t touch that section”)
- Making cherry picking easy
- I want to prototype a collaborative writing tool as a testing ground for the version control stuff
- Also had the change to give feedback to a few friends on writing and one big pain point is just finding the best way to comment/give feedback. We always just paste in Google Docs and pepper the document with comments and suggestions but there needs to be a better way than this
January 13th
- Had a lovely chat with Quinn from Fission and wow that was amazing
- For more context, Quinn has been working on Dialog which has recently been renamed to Rhizome (!!!)
- Feel like its a case of convergent evolution that we are separately coming to roughly the same conclusions about what a ‘post-modern’ database should look like
- We talked about pvh’s thoughts on RDFs and realized that actually, we don’t necessarily need to expose this complexity to the user! We can have Datalog as a compilation target
- Also caught up with Kleppmann for the first time in a while. He seemed really excited by the interface stuff I’m thinking about for CRDTs and version control in a collaborative setting!
January 12th
- More on Datomic!
- Why immutability actually makes sense when representing real-world things:
- “Facts don’t go away. If the princess’s tastes change so that she prefers sriracha, it’s still useful to know that in the past she preferred mustard. More importantly, new facts don’t obliterate old facts.”
- That’s because time only works in one direction in the universe (that we know of): forward
- So by encoding causal dependencies, we get this for free
- Merging reallly old changes (localfirst/auth discussion)
- Big usability problem for distributed apps. If a long-dormant device can come online and introduce a single operation that overturns months’ worth of activity, people will perceive the app as unstable — even if there’s no malice and no security issues involved.
- Can we set limit
Lon how far out of date a device can be before we require it to catch up before submitting changes? The idea would be that you couldn’t base a change on a head that’s older than that. Instead you’d have to catch up with the latest information, and then rebase your change onto the current head.Lis a wall-clock timestampLis a logical timestamp
January 11th
- Deconstructing the Database, talk by Rich Hickey, author of Clojure, and designer of Datomic
- “I think one of the questions we have in revisiting the architecture of a database is, what’s possible? How much of the value propositions of databases can we retain while tapping into some of the new value propositions of distributed systems, in particular, their arbitrary scalability and elasticity?”
- “Other problems we have in general when we talk about traditional databases are flexibility problems. Everyone knows the rigidity of relational databases and the big rectangles. We also have the artifice of having to form intersection record tables and things like that”
- I love (and strongly agree with) Datomics approach to thinking about databases
- Had a brief chat with pvh about this same topic and he interestingly disagreed. Speaking from empirical evidence, RDF and tuples have never really worked. It’s hard for people to wrap their heads around
- Disk-locality considered irrelevant
- Reading from local disk is only about 8% faster than reading from the disk of another node in the same rack
January 3rd
- Rollback-based mode more thoughts
- Attaching an epoch to each non-commutative operation (this is effectively making the implicit causal dependency explicit)
- Separates non-commutative and commutative sequence numbers
- Ordered so epoch numbers are treated as earlier (opposite to sequence numbers)
- Then, if we add rules to deal with conflicting actions add a query/view level
- e.g. how to deal with an insert op by author A if author A’s access to the document is revoked
- Attaching an epoch to each non-commutative operation (this is effectively making the implicit causal dependency explicit)
- I think the research direction I want to explore further is expressing CRDTs as queries over an ever-growing fact-base (Represented as a )
- Commutativity is trivial using the set union operator
- Fact-base is a 6-tuple
- Entity ID (E)
- Attribute (A)
- Cardinality of one or many
- Value (V)
- OpID (Id)
- CausalOrigin (Origin)
- Retracted (Del)
- This is equivalent to a delete operation
- Incremental View Maintenance
- Building indexes using Prolly Trees for optimized lookups
- Questions
- How might capabilities be modelled? And private data?
- Autocodec for translating attributes between applications?
- Another possible route… exploring UI/UX of CRDTs as time travel
- More suited as a short, term-long project (and potentially a project I can do with Ink & Switch)
- Visual drag-and-drop interface
January 2nd
- An idea: Hashgraphs + safety-certificates for non-commutative operations
- Eager mode (similar to Delta-CRDTs)
- Flood communication
- Assumes unique ID for each operation
- We track a list of all peers who we have received messages from (a list of
AuthorIDfor each neighbour) - Each time we receive an operation with ID
OpIdwe haven’t seen before and successfully apply it, we broadcast anACK(OpId)message to all neighbouring peers - For each op
OpId, we locally track the set of all peers who have acknowledgedOpId - Once we have received an acknowledgement from each of our neighbours for a single operation (call this the safety-certificate), it is safe to apply a non-commutative operation on it (we can now delete it or deliver any causal dependents)
- This works for applications with explicit causal dependencies (e.g. text editing)
- However, it is a bit more difficult to reason about for implicit causal dependencies (e.g. access control)
- Consider two admins A and B who are accessing the same document.
- Concurrently:
op1: Admin A types the letter ‘a’ in the documentop2: Admin B revokes A’s access to the document
- The problem is that the algorithm treats these as operations that commute when the clearly don’t! Some peers may see ‘a’ (if they receive
op1ahead ofop2) and others will not (op2ahead ofop1soop1becomes invalidated)
- Concurrently:
- This is solved with the epoch-based approach below
- However this requires fixed membership as it seems to completely mishandle cases where members leave the group (can no longer get a whole safety-certificate)
- This is potentially solved by signalling departure and setting an inactivity timeout for nodes
- Though using heartbeats to refresh inactivity timeout feels counter to the whole CRDT ethos of offline support
- This is potentially solved by signalling departure and setting an inactivity timeout for nodes
- Rollback-based mode
- Attaching an epoch to each non-commutative operation (this is effectively making the implicit causal dependency explicit)
- This implies that each CRDT requires the ability to undo and redo operations between non-commutative operations
- Not all computation is reversible though (e.g. entropy increasing operations like blurring), how do we reconcile this?
- Can we utilize the hashgraph to do git-like rebasing to avoid having to implement a redo?
January 1st
- More thoughts on access control
- Distributed Access Control for Collaborative Applications using CRDTs uses a total ordering of roles in order to resolve access conflicts
- However, in the case of two top-level administrators revoking access, the same problem occurs
- Additionally, it is not not always possible to totally order a set of permissions. Consider one person with access to file 1 but not file 2 and another person with access to file 2 but not file 1.
- “Combining CRDTs for data with CRDTs for policies raises several challenges. Conflicts between two concurrent operations based on diverging policies cannot be safely resolved.”
- They resolve this by attaching an epoch to each policy change
- The epoch doesn’t grow in size, but merely refers to a parent operation that last changed the policy.
- This implies that each CRDT requires the ability to undo and redo operations between epochs
- Undo-redo may be expensive if it happens a lot! The assumption here is that policy changes are rare so this doesn’t happen very often
- They resolve this by attaching an epoch to each policy change
- Garbage Collection
- Two part series (pt1 and pt2)
- Why GC is hard:
- First, establishing the stability of an update as described in the paper assumes that the set of all replicas is known and that they do not crash permanently.
- Inspiration from Delta-CRDTs
- In the causal-consistency-ensuring anti-entropy algorithm. When a node sends a delta-interval to another, the receiving node replies with an acknowledgment after merging the interval into its local state. A delta that has been acknowledged by all of a node’s neighbours is then garbage-collected
- Synchronized GC
- Under two-phase commit, each replica will vote on whether each tombstone is still necessary.
- QCs for GC?
- Type-level consistency guarantees?
- Source
- Just as ‘function colouring’ exists as a way of distinguishing async and non-async functions, what if we could colour other sorts of system models?
- CockroachDB Layers
- SQL Layer: translates high-level SQL statements to low-level read and write requests to the underlying key-value store
- Transactional KV: Requests from the SQL layer are passed to the Transactional KV layer that ensures atomicity of changes spanning multiple KV pairs
- Distribution: monolithic key space. Range-partitioning on the keys to divide the data into contiguous ordered chunks of size ~64 MiB, that are stored across the cluster. We call these chunks Ranges
- Replication: consensus replication using Raft across replicas
- Storage: KV-store, use RocksDB
December
December 30th
- Reading about Datalog as a way of expressing CRDTs… some promising work in this direction
- I think there’s a pretty clear articulation of this over SQL as this allows us to separate data representation from data views in a more clear way
- This also means we can do away (?) with SQL migrations
December 28th
- Finally finished up my blog post on Communal Computing! It turns out, sharp feedback leads to better writing, who would have ever thought :’)
- Did a bit more thinking about Kleppmann’s Recovering from key compromise in decentralised access control systems
- I feel like there is a close connection to be made with Arrow’s Impossibility Theorem but haven’t been able to formally show it
- Perhaps using Quorum Certificates for group membership voting?
- These can be built offline (and even allows for receiving updates offline) and sent when a user is back online.
- A membership change is then considered stable when it receives 2 unique supporting QCs. Of course, this only works with .
- Voting members: all members of the group which were members prior to the membership change
- Mutual removal: going with something that is intent-preserving feels important here. One potential way to resolve this is to restrict membership changes to at most one removal per round. Requiring 2 QCs would mean that we have consensus on which group member to remove and removing a single member cannot possibly cause a conflict. (this may not be ideal for situations where a large number of group members are removed but I suspect these cases are very rare)
- Found out that Beaker Browser is now archived :(( A really interesting retro that has a lot of good reflections and learnings for anyone working on p2p tech
- Major challenges:
- Without some logically centralized repository of data or router of messages, you struggle with discovery and delivery.
- Users don’t stay consistently online and connections will randomly fail, so you stuggle with availability and performance.
- Initial connections and thus time-to-first-paints are slow, which is very bad news for web browsing.
- Debugging is quite hard.
- Managing resource usage on the device is hard.
- Scaling a user’s view of the network past (say) 100k users is pretty much out the window because you’re not sharing indexes; rather, you’re having each device build the indexes locally.
- Is this fixable with Prolly Trees?
- “As decentralizers we may be pursuing a mission, but our work only wins in the market, and to win in the market we need to think like entrepreneurs. Ultimately, my lesson learned is that mission needs PMF.”
- Major challenges:
- Coordination in CRDTs? Inspiration from the TreeDoc paper
- TreeDoc is occasionally flattened from a tree into an array to cleanup tombstones and balancing issues
- However, this is not commutative. TreeDoc solves this by using an update-wins approach in a two-phase commit protocol
- The site that initiates a flatten acts as the coordinator and collects the votes of all other sites. Any site that detects a concurrent update to the flatten votes “no”. The coordinator aborts the flatten if any site voted “no” or it never received a response
- Supporting large groups of replicas
- Uses hubs to help scale — see Network Theory
- Core: well-known nodes that are well-connected
- Nebula: all other nodes
- Epoch-based flattens
- Each flatten – each change of epoch – changes the frame of reference for TID
- A core site maintains a buffer of updates messages it needs to send to the nebula, some in old epoch some in the new one
- A nebula site maintains a buffer of update messages to be sent to the core; these are all in the old epoch
- The nebula must first bring the out of date messages into the new epoch to replay them
December 14th
- Had a wonderful chat with Brooklyn from Fission. We nerded out a lot about capabilities, lot’s more reading for me to go through:
- Capability Myths Demolished
- Recovering from key compromise in decentralised access control systems by Kleppmann and Bieniusa
- Robust Composition: Towards a Unified Approach to Access Control and Concurrency Control
- More research direction refinement!!
- Released some unfinished work and asked people close to me to read it
- A lot of feelings stewing around feeling not confident in my own work after the average sentiment was lukewarm at best
- I think it stems around sharing inherently incomplete/vague/in-progress work. It’s a very weird frustration that comes from mismatches between my mental model, the work itself, and the readers mental model
- But this is the great part of feedback!! Even though emotional brain says that “oh no, harsh feedback scary”, it is actually really constructive and helps me articulate my thoughts better. I’m going to try to make a piece of writing I’m fully proud of when I finish exams (soon!)
December 1st
- Well would you look at that… it’s December
- It’s been a week but the hype from my BFT JSON CRDT project has finally started to cool
- Over 10k people viewed the blog post for meaningful length of time and HN was surprisingly nice about it :’))
- A bunch of people reached out asking to chat more about CRDTs (some even asked if I was open to contracting!) Super cool to find more people working in this space and who are as equally excited about it as I am
- Most importantly, Kleppmann reached out! I had messaged him to schedule a call at some point but we never found the time. But he saw (and even retweeted!) my blog post and really thought it was solid work.
- He asked if I would be interested in doing a PhD with him at Munich University. Unfortunately, visa problems combined with the requirement that I get a Masters first mean that I probably won’t be taking him up on this offer.
- However, we are still going to be formally collaborating on some papers regardless which I am still kind of in shock over. This felt so full circle for me! I quite literally started this summer with zero distributed systems knowledge and now I get the chance to collaborate with one of the people on the bleeding edge of distributed systems knowledge and research. Bonkers!!
- Today, I spent a lot of time thinking about the technical architecture of Rhizome now that I have the experience of the project behind me. Updated some diagrams in Rhizome Proposal but TLDR;
- EAV tuple store not append-only log
- UCAN good
- CRDTs instead of Raft for most things, CALM Theorem may be useful to figure out when coordination is necessary
- Open questions
- How will we mark state as requiring coordination?
- How do we efficiently reconcile big tuple stores?
November
November 18th
- I know I’ve been neglecting this research log a little bit…
- I’ve been squeezing time wherever I can to work on this silly little project. As of 11:59pm tonight, I have finished the project and fully written out a 6.2k word blog post (read it here) on it to pair
- This project realllyyy pushed me to my limits in terms of my engineering ability
- So many times I doubted if something was even possible or not and many late nights of pushing off other responsibilities to get more hours on this silly little thing
- I always knew I’d finish but to be honest, I can’t really believe its over
- There’s still more projects I want to work on but in the meanwhile… time to take a small break : )
October
October 27th
- Adding JSON support is harder than I expected!
- Mostly taking inspiration from yet another Kleppmann paper
- Insert
- Ignore if we have it already
- Create new entry in table with hashed
OpIDwithis_deleted = false
- Update
- All the steps of delete and insert
- Delete
- Lookup prev
OpIDand mark it as deleted
- Lookup prev
- Probabilistic decay mechanism for CRDTs
- ‘Remind me…’ mechanism
October 24th
- Privacy preserving CRDTs??
- Turns out Automerge is actually fast now
- They’ve refactored their codebase significantly and use a b-tree similar to Diamond Types
- Ed25519 should be able to sign + verify upwards of 100k signatures/s on a 1 GHz processor so I need to make some improvements here
October 23rd
- Another great talk on WNFS by Brooklyn Zelenka
- The whole ‘ask for permission’ thing isn’t actually new!
- Our phones already do this: “Google Photos is asking permission to access your camera roll”
- New Directions in Cloud Programming
- The way we write distributed systems today is like writing assembly by hand — incredibly error prone
- Creative programmers are held back by the need to account for these complexities using legacy sequential programming models originally designed for single-processor machines.
- We need projects like Bloom/Hydro that help with ‘compiling away’ those concurrency semantics
- The way we write distributed systems today is like writing assembly by hand — incredibly error prone
October 22nd
- Had a random question about a paper that Kleppmann wrote and just straight up messaged him on Twitter LOL totally not expecting him to respond
- He did! Within just a few hours and helped to confirm that I did in fact need to sign messages using asymmetric cryptography to prevent forgery
- Also, Nalin helped to clarify a lot of my understanding for cryptography which was super nice of him :))
- Finally finished implementing tests for BFT and… it seems to work?? Kinda bonkers that I’ve been working on this project for almost 2 months now. Probably the most technically involved project I’ve done that integrates so much stuff I’ve learned in the past few months in systems design, networking, cryptography, and information theory
- Just need to finish up hashgraph reconciliation and the JSON aspect of the CRDT and should be good to go
- Thinking about a potential sharded/partitioned design for a triple store DB
- Using distance metrics like Kademlia DHT does?
October 20th
- Started writing post on a BFT JSON CRDT
- Ran into a potential problem with message forgery…
- Seems like Kleppmanns’s Paper doesn’t address cases where, say a Byzantine node tries to send a message on behalf of another node (as it knows the unique IDs of other nodes) and forges an update.
- This is possible as the unique ID doesn’t have any other properties that guarantee that only that the node with the ID can send that message.
- We would potentially need some sort of PKI assumption where the unique ID of a node is its public key and the ID is the signed digest of the message
- This is (sort of) confirmed in Kleppmann’s 2020 paper
- “We assume that each replica has a distinct private key that can be used for digital signatures, and that the corresponding public key is known to all replicas. We assume that no replica knows the private key of another replica, and thus signatures cannot be forged”
October 19th
- Picked up Seeing Like A State again, it feels a lot more relevant to my research now for some reason
- We can think of a triple store as a distributed and fragmented SQL database, where instead of tables with rows and value, we have entities with attributes and values.
- Any application can declare new attributes or alias an attribute to a more common one
- The most important part is that applications that share attributes can automatically interoperate their data
- The harder question is how to build good indices so that when the number of triples grows really large, we still get fast queries
- I suspect there’s a lot to learn from decades of SQL index/query optimizations
- Would like the syntax to borrow from GraphQL
- This type of ‘decentralized’ database means there is no canonical schema. You can’t mistake the map for the territory because everyone has their own map and can’t force others to view the ‘truth’ of the world through your map
- Forcing ourselves into schemas make it hard to innovate
- To make new things requires us to provide migration paths forward or just accept stagnation
- It inadvertently shapes what people build — leads to easily legible/classifiable applications (see: post on digital identity and legibility)
- It is treading outside the map that gives us innovation
- This would give us contextual data for app specific data
- We can see this as analogous to context dependent personalities (again, context collapse bad)
- We can think of a triple store as a distributed and fragmented SQL database, where instead of tables with rows and value, we have entities with attributes and values.
- Spent a lot of time trying to optimize
bft-json-crdtto squeeze more performance out of the base list CRDT but to no avail- Realizing this was kind of a waste of time as I was just using this is a proof-of-concept
- Especially if I want to focus on something that’s more like a triple store, a list is kind of useless lol
- Going to focus more on the BFT and JSON-aspects of this project
October 12th
- Ok well… it’s been 3 weeks since I last wrote an update. School has been busy!
- I got really stuck with Rhizome work so I took a week and a bit off to work on Tabspace and launched it. It felt good to launch something and ‘unstick myself’
- Got more motivation to work on
bft-json-crdtand started a more methodical approach to debugging (rather than just changing index offsets and rerunning LOL).- Eventually pinpointed two bugs:
- Not accounting for repeated delete elements
- Not properly updating the internal sequence number
- Once these were fixed, it kind of just worked! Of course, the performance isn’t great but it still happens to be ~4x faster than the base Automerge implementation B))
- Eventually pinpointed two bugs:
September
September 30th
- I think decision is that going down splay tree route is not worth and I’ll just do this using a simple vector LOL
- Been slowly but surely working away at this BFT CRDT implementation in Rust
- Figuring out some tradeoffs, I already rewrote the crate from using doubly-linked lists to using a splay tree but maybe this isn’t the right data structure either
- Desired attributes
- Fast insert at arbitrary location
- A decent chunk of edits happen in places that are not the start or end of edits!
- Ideally less than
- Ordering in list is a local property
- It should be easy to figure out location of a node given its ID
- Insert time for integrate
- Find right position to insert
- Comparison involves looking up position of parent
- Insert
- Find right position to insert
- Update should be considerably faster than render (which realistically doesn’t need to happen that often)
- Candidates
- B-Tree (Diamond Types uses this)
- Node location is not local (worst case indirections)
- Insert time for integrate
- Find right position: amortized
- Finding parent is amortized
- Overall is amortized
- Insert: (need to recount up the tree)
- Find right position: amortized
- Note: has pretty good cache locality because you can read entire lines of nodes into memory
- Requires indexing by character position which is not ideal
- SplayTree
- Node location is not local (average case levels of indirection and potentially worst case)
- Insert time for integrate
- Find right position: amortized
- Find parent is amortized (we can use a binary encoding of the search path as an index)
- Overall is amortized
- Insert: (need to rebalance up the tree)
- Find right position: amortized
- Note: rebalancing may not be bad in terms of time complexity but sucks because of memory locality
- SplayTrees are binary search trees which can lead to some deep trees which require many pointer dereferences
- Are there -ary SplayTrees??
- Doubly Linked List (Yjs uses this)
- Node location is not local
- Insert time for integrate
- Find right position:
- Find parent is
- Overall is which is slow on many concurrent inserts
- Insert:
- Find right position:
- Vector
- Node location is local
- Insert time for integrate
- Find right position:
- Find parent is
- Overall is which is slow on many concurrent inserts
- Insert:
- Find right position:
- Fast insert at arbitrary location
- Catching up today on a bunch of talks + reading
- Wonderful talk by Brooklyn Zelenka (CTO of Fission)
- “The limitation of local knowledge is the fundamental fact about the setting in which we work, and it is a very powerful limitation” — Nancy Lynch, A Hundred Impossibility Proofs for Distributed Computing
- CIDs give us global pointers that we can all agree on (these are hard links, unbreakable)
- Compared to URLs (soft links, kind of like symlinks, can break). Point to a latest something
- Wonderful talk by Brooklyn Zelenka (CTO of Fission)
September 3rd
- Bunch of weird Rust things today
- Generally, use
.take()onOption<Box<T>>and.clone()onOption<Rc<T>> .as_ref()is like&but generally acts on the internal reference (i.e. on anOption<T>,&gives you&Option<T>whereas.as_ref()gives youOption<&T>)- Additionally,
.as_deref()basically is just.as_ref()with an additional.deref()on the unboxed value (effectively performing deref coercion) <option>.map(|node| &**node)is equivalent to<option>.as_deref():
- Additionally,
Rc::try_unwrapwhich moves out the contents of anRcif its ref count is 1
- Generally, use
September 1st
- CAP Theorem Tradeoffs and A Certain Tendency Of The Database Community
- Rhizome Architecture: now with triple-stores :))
- Root: identity + persistence layer
- Standalone app to manage identity + storage
- Support multiple identities
- essentially a managed
DID:keythat controls a set of IPFS nodes to pin certain things - ‘open [app] on your computer’ type authorization for web applications
- Trunk: application layer
- Data framework layer: distributed triple store
- rust → compiled to WASM for web
- each node has its own triple store that is created from an append-only data log
- each triple contains ID, relation, and value
- how do we do realllyyy fast triple search? on multiple relations?
- how do we pack memory efficiently for this?
- we can ‘subdomain’ relations (e.g. it belongs to a certain set of schemas or application) using a trie
- optional
author_idfield to link to Root
- Query layer: turns the triple store into live views that are interpolated
- Display layer: uses the views to perform calculations and display things
- Bring your own data: an application has a specific fingerprint
- Defines exactly which types of triples it reads/writes
- Enables you to invite another user to ‘bind’ to your current application state (similar to ‘invite’ to collaborate on a document or something)
- Data framework layer: distributed triple store
- Ditto: publicly contributable schema and API definitions
- Root: identity + persistence layer
August
August 31st
- What would it be like to build in interpolation into the state replication level?
- e.g. similar to Quake 3’s Networking or perfect-cursors both do 3 types of smoothing:
- Interpolation: If it knows the state of the world at time t and at time t+50 ms and it needs to render additional frames between those points in time, it interpolates the positions of all visible objects between their known two states.
- That means that when the client is rendering the frame at t+16 ms, it already needs to have received the information about the server frame from t+50 ms!
- The only way that is possible is if the client intentionally delays its view of the world in relation to what it’s receiving from the server.
- Extrapolation: What happens when the network packet containing the next snapshot is delayed or lost and the client runs out of states to interpolate between? Then it’s forced to do what it normally tries to avoid: extrapolate or guess where the objects will be if they keep moving the same way they’re currently moving.
- Prediction: The only exception here is player input. Instead of waiting for the server to do that and send back a snapshot containing that information, the client also immediately performs the same player movement locally. In this case there’s no interpolation - the move commands are applied onto the latest snapshot received from the server and the results can be seen on the screen immediately. In a way this means that each player lives in the future on their own machine, when compared to the rest of the world, which is behind because of the network latency and the delay needed for interpolation.
- See also: GGPO which is heavily used in real-time fighting games
August 30th
- A Graph-Based Firebase
- Turns out most modern real-time applications look something like this:
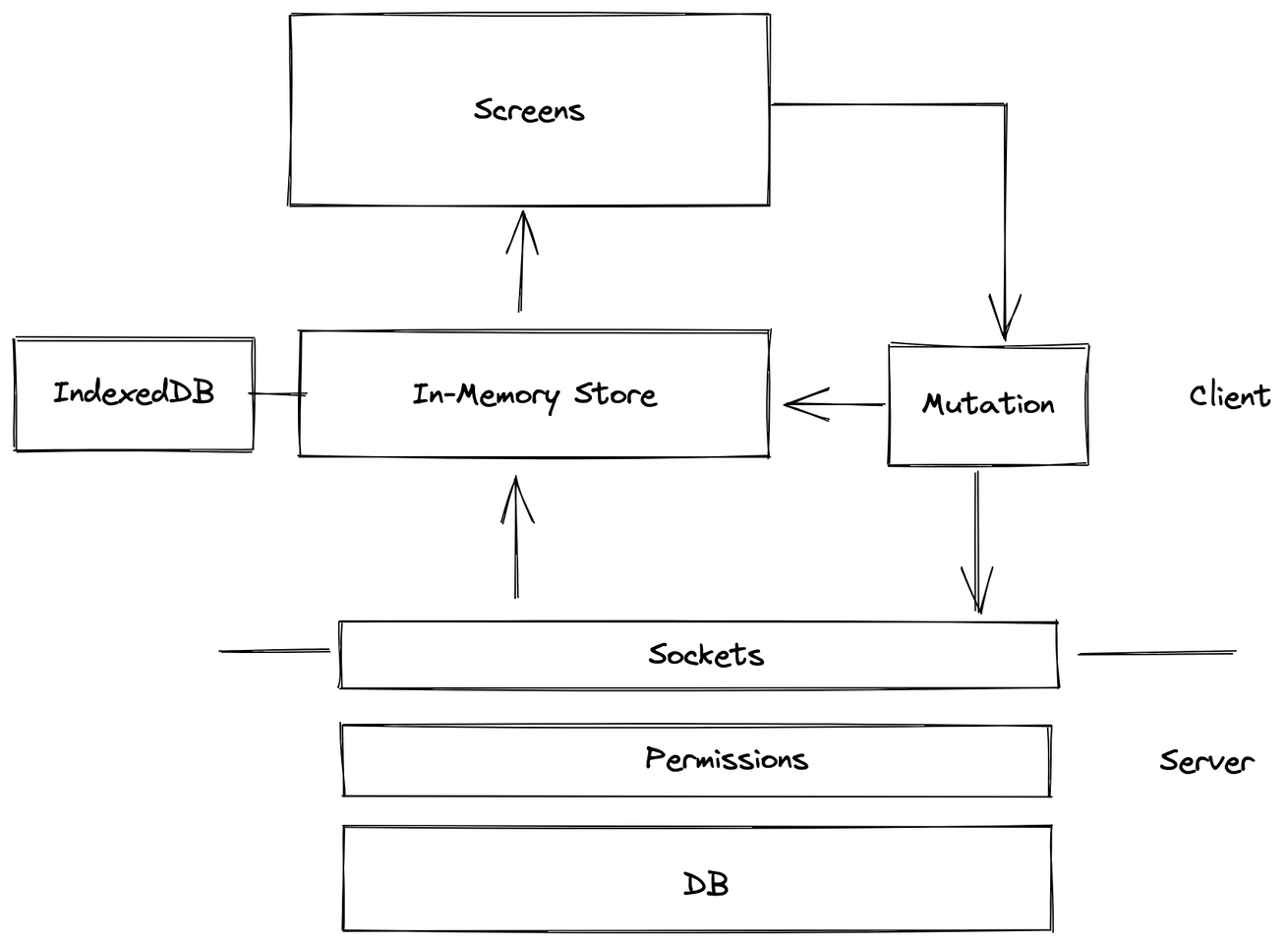
- SQL seems to be too complex. The common request for data in front end is a complex case to express to SQL. “We shouldn’t need advanced features for common cases.”
- The most common query is our “fetch nested relations”. This should be supported first class
- We can potentially emulate this using triple stores built on top of an append-only CRDT. Datalog and triple stores have been around for decades. This also means that people have built reactive implementations.
- Unsure if we can leverage CALM as its Datalog but not monotonic (facts can be retracted)
- Turns out most modern real-time applications look something like this:
- DAG instead of append-only log
- “Both of these abilities follow directly from the explicit embedding of causality into a DAG, with time travel being analogous to a traversal over that graph” Dialog
August 23rd
- Phillip Wang’s talk — related to reflection post
- tldr; We should leave space in our lives for finding conviction in things we work on
- How do we enable the “other” path for high achievers? Not the one where they can just work at a big company, get paid lots of money, life a cozy life, but the harder path in which they truly question the why and ask themselves what they find truly fulfilling
- Fully commit to one thing — deep beauty in choosing, against optionality
- How does this fit into the exploit-explore tradeoff?
- Feels like there’s a necessary balance between
- being deeply invested in something to be able to have a level of almost unwavering conviction
- not being so deeply invested that you are oblivious to exploring better potential options
- Leaving space to have conviction is inherently a privilege, how might we enable local spaces of abundance (places for play) so that more people have that privilege?
- This also feels like a generational thing. My parents first immigrated to Canada when I was around 3. They’ve spent a big chunk of their lives worrying about how to meet basic survival needs
- I grew up with enough resources around me that I’ve begun looking for what I have conviction in; what I feel invigorated by
August 22nd
- Justin Glibert’s talk
- tldr; composability + permissionlessness enable novel affordances we haven’t seen before in digital systems
- What if… Kademlia-like XOR distance metric but for SMR
- Permissionlessness is an important characteristic to enable innovation and emergent behaviour
- See also: Simon Harris on the same topic
- “Many tales exist of [the origin of the bistro]. Some say it was working-class landlords opening their kitchens for extra income. Others say it was the Auvergnats, immigrating to Paris from what is today central-south France, who first worked as rag-pickers, then wood and coal sellers, then metalworkers, who created small working-class restaurants to supplement their income. Either way, it was not planned or engineered, but simply not-disallowed. There were no rules in place to stop this invention.”
- Same with YouTube which started out as a dating app but then let people upload anything. The users, not the website creators, found its real uses
- Does this conflict with the fact that good DX/UX comes with strongly opinionated use cases?
August 19th
- Packing and flying back to NY for Hack Lodge! Will be posting an ongoing thought stream :))
August 18th
- Preparing workshop notes to talk about computer networking + P2P
- Feelings rant — I feel an odd and unusually heavy sense of impostor syndrome today. Going to write out more stuff in this blog post I’m going to flesh out
- Frustrated by this video by one of the founders of the Browser Company
- Their vision is that the ‘next generation’ of computers — after the mainframes and personal computers — is the internet computer, where everything we do happens in the cloud and our machines are just dumb portals to access these
- We can’t be going back to time-sharing! Time-sharing was only a thing because we didn’t have access to powerful enough consumer hardware — this is no longer the case
- Not only do you need to always be connected to the internet to use it, it is also incredibly Orwellian except with all-powerful companies instead of states which have detailed metrics into how you conduct every moment of your digital lives
- Josh seems to be conflating local-first software with software that is not connected to the internet
- Just because our data lives locally on our device, does not mean your work is trapped on one device
- I think the future is a happy middle between completely offline and completely online — we’ve pendulum-ed to both sides of the spectrum and are perhaps settling on the reasonable option
- Servers have a role to play in the local-first world — not as central authorities, but as “cloud peers” that support client applications without being on the critical path. For example, a cloud peer that stores a copy of the document, and forwards it to other peers when they come online, could solve the closed-laptop problem.
- “Nobody makes native apps anymore”
- People want the performance of native apps without having to maintain many codebases across them.
- As more and more apps become ‘internet-first’, libraries for storing things locally and reconciling them with remote copies of that data have not made nearly enough progress.
- As a result, many ‘native apps’ are just wrappers for a single source of truth that lives on a remote server. This is not ideal in terms of many things but mostly performance and data ownership.
- In a million years time when they dig back down in the archive history of our digital footprint, they won’t see vibrant replicas of the web but rather a digital dark age.
- The documents created in cloud apps are destined to disappear when the creators of those services cease to maintain them.
- Cloud services defy long-term preservation.
- No Wayback Machine can restore a sunsetted web application.
- The Internet Archive cannot preserve your Google Docs.
- Their vision is that the ‘next generation’ of computers — after the mainframes and personal computers — is the internet computer, where everything we do happens in the cloud and our machines are just dumb portals to access these
August 17th
- Really diving into whether a dual optimistic replication (CRDT) + transactional replication (Raft SMR) approach is needed or if one will do
- Optimistic replication
- Best for global collaboration. Local nodes can still be speedy even with collaborators from across the world
- Can lead to inconsistent states if not careful (again, can use a DSL to help catch these types of errors but it just becomes difficult to write and will require extra research time)
- Alternatively, have no global invariants. JSON-style data structure
- Strong eventual consistency data stores (e.g. CRDTs) will hit a few million TPS per second locally for sticky writes with actual TPS being roughly (where RTT is ~500ms at worst, ~150ms usually)
- Bandwidth use is (just send to all nodes)
- Latency is (don’t need to wait for reply)
- Transactional replication
- Easier to reason about for application developers
- Atomic commit-type data stores (e.g. SQL, CockroachDB) still achieve upwards of 28k TPS in a single-region zone. In a global environment, TPS will be roughly . This means that if you have a very global team working on something, synchronously collaborating something will still be quite laggy (~1TPS). Doesn’t work on an ‘inter-planetary scale’!
- Bandwidth use is where is number of rounds of the consensus mechanism
- for initial request and rounds of communication between all nodes (overhead can be reduced to if normal state is )
- Latency is
- Hybrid
- Best of both worlds, but the most complex to reason about and write programs for
- Alternatively… what if we expose a simple KV store using CRDTs to exchange routing info? This would open it to easily layering real-time applications on top (e.g. video calls, WebRTC). This eliminates the need for a signalling server
- This can technically be done already by the user in transactional replication model if they want
- Optimistic replication
- Addendum: the CALM Theorem conjectures that if program state can be expressed in monotonic Datalog, it can safely use optimistic replication. If we can always express something using an immutable Merkle-DAG with occasional consensus for GC, shouldn’t this work?
- Have one SMR instantiation of the SMR algorithm per application
- How do we do live reconfiguration of cluster quorum size?
August 16th
- Finally made my way through all my research papers. There’s a weird peace to have no open browser tabs, down from around ~75 open
- Thinking about access control and revocation. Especially for add-only data structures, how can we prove data has been deleted or removed?
- What is the base metaphor we should use when building applications?
- A chat except the base unit is not text but structured data. Call this the ‘event history’
- This implies a certain causal history and a partial ordering
- Trunk
- User defines
data Op = ...: All possible operations of the appdata State = ...: Application stater :: State -> Op -> State: The reducer functions0 :: State: The initial state
- How is state persisted?
- User defines
- Root
- Identity
- A
did:keyis generated for every history - One root IPFS document tracks all active
did:keys associated with a root DID
- A
- The Merkle-DAG will be anchored using IPLD, this means that hopping cloud providers is easy as everything is content-addressed
- Storage Providers
- Providers should pass a suite of unit tests for correctness in terms of satisfying certain behaviour.
- With this model, all a storage provider needs to do is pin a few CIDs
- This takes care of data availability… but what about liveness? This is where SMR comes in
- Identity
- Ideal SMR algorithm properties
- Favour liveness over consistency when potentially majority replicas are offline (i.e. handle all cases in asynchronous crash-stop model)
- Should scale well with number of participants
- Synchronization should not be on the critical path (read: CRDTs where possible, consensus otherwise)
- Collaboration over consensus (i.e. try to preserve user intent where possible)
- Things to figure out
- When is it safe to GC?
- Is it worth writing a DSL that compiles down to different host languages? This could be really useful to provide helpful compile-time checks
- Basically to adhere to CALM, we want to make it easy to write synchronization free code (similar to Rust and how it makes it easy to write GC-free code)
- Generate the appropriate boilerplate for code that requires synchronization
- Have a good standard library of data structures that are primarily synchronization-free
- Potential demo apps
- Basic chat app
- Google drive/Dropbox clone (testing large op/diff sizes)
- Tool for thought, Google Docs-like writing primitive (testing permissioned access and collaboration)
- Semantic diffing, live
git - Minecraft or other real-time game (testing latency)
- EVM (testing expressiveness)
- Synced file system.. with editing and hosting of local-files baked in
- co-creating w ebsites live, similar to Beaker Browser
August 14th - 15th
- Organized The SF Commons: Hack Day #0 with Athena! A non-zero number of people were like “Hey! I’ve read your blog before” or “I love the work you do” and it was a little surreal
August 13th
- Visited the Computer History Museum today! Lots of interesting tidbits on how we got to where we are today
- If economies of scale favoured large consolidated computer systems how did the personal computing revolution happen?
- One reason is that the main bottleneck to adoption back then was the price. But as Moore’s Law continued to hold, hardware became exponentially cheaper due to innovations in chip design, manufacturing, storage, etc.
- People started buying it because companies like Apple started branding personal computing devices not as something reserved for only programmers and geeks:
- “Since computers are so smart, wouldn’t it make sense to teach computers about people, instead of teaching people about computers?”
- There were magnitude level improvements over existing technology. The census for example, took 10x-100x less time using computers
- How can this be applied to the moving away from large, consolidated, monolithic applications to the personal application era?
- “Why is it so hard to own my own hardware?” roughly translates today to “Why is it so hard to own my own data?”
- Explaining data availability like the differences between calling versus texting someone
- Calling means that the other person needs to pickup
- Texting means that you can still communicate without both being on a call
- If economies of scale favoured large consolidated computer systems how did the personal computing revolution happen?
August 12th
- CALM Theorem and CRON Theorem: Basically, avoid coordination where possible, it makes things slow. When we can avoid or reduce the need for coordination things tend to get simpler and faster. This theorem tell us when it is safe to avoid coordination.
- I wonder if there’s possibility here to write a DSL (perhaps similar to BLOOM) that compiles to JS/Rust/etc. but also checks for monotonicity properties.
- Similar to that Quilt piece on why hiding network complexity in APIs is bad, perhaps baking in these inefficiency warnings (i.e. warning on ‘accidental’ coordination, is there a way to refactor this program to use a different set of data structures which don’t require coordination) into the language
August 11th
- Notes on Braid HTTP, Yjs, SSB, OrbitDB
- Quilt has a great piece arguing for more CRDTs and why APIs are lacking and what the next logical step is
- Put more simply, going back to picking on APIs, what will complete this analogy?
assembly/C : Java/Python/Clojure :: APIs : ??? - To quote Leslie Lamport: “Most people view concurrency as a programming problem or a language problem. I regard it as a physics problem.”
- Sadly, looks like the project is no longer maintained
- Put more simply, going back to picking on APIs, what will complete this analogy?
August 10th
- Notes on HotStuff, HoneyBadgerBFT. HotStuff seems to be a really useful lens to analyze future protocols as it is a general framework for expressing byzantine fault-tolerant SMR.
- Lots of paper reading… I feel a little burnt out. I’ve been spending almost 15h days just trying to mental sponge as much as this as I can.
- I think I’m getting enough sleep and my eating habits aren’t terrible but my body seems to disagree. My eye sometimes just twitches randomly and my stomach has a certain tightness to it that I can’t really describe well.
- A bit of a slump day. Really spent the last month just reading about consensus protocols in partially synchronous system models only to discovery that what I was really looking for was consensus protocols in completely asynchronous system models (which handle cases where potentially majority replicas are offline).
- I realized this as I was digging into the very last PDF I had in my browser tab on consensus algorithms — the last of 50 or 60 odd papers I made my way through.
- In this last paper, I found out about the LR Permissionless Result which was derived earlier this year in February. It rules out the possibility for deterministic consensus in a Byzantine, permissionless model, which voids my current assumptions about the right type of consensus model for Rhizome.
- I don’t think the research and learning went to waste per-se, I feel like I really learned a lot, but it sure feels like that whole month went to waste — none of the protocols are of any direct use to the project. I just feel incredibly frustrated.
- A summer retrospective. Anson encouraged me to write a more in-depth reflection on my research processes. I mentioned on a call that I felt unhappy with my progress this summer. I think the bulk of it comes down to doing way too much reading and not enough building and producing things.
- A large part of this I think comes down to underestimating just how much I didn’t know about the space to begin with
- Every paper I read opened 2-4 new ones. An unknown concept or definition meant another day or two to get familiar with the literature surrounding it. It wasn’t until a month ago that the number of tabs I had open started to go down.
- It feels like the attitude I’m taking towards research is one of bumping around in the dark. For the most part its enjoyable and exhilarating, finding things out for the first time.
- There’s a certain joy to putting yourself in an environment where you can discover things for yourself. I can ask for help when I need it, but most of the time I’m puttering along at my own pace.
- This is roughly what my self-satisfaction curve looks like for self-motivated exploration:
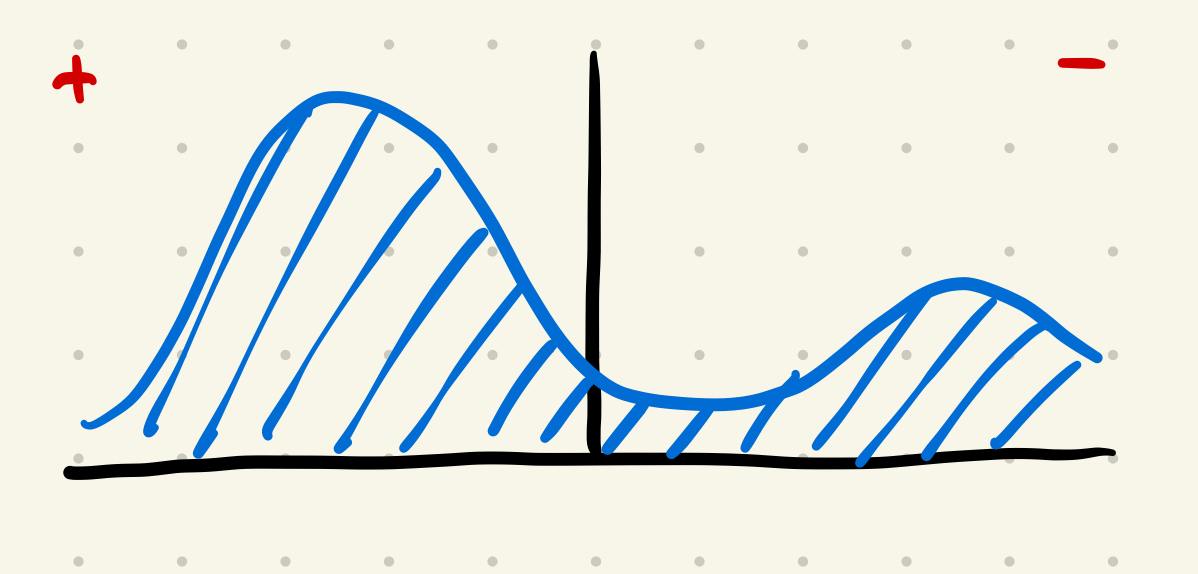
- This is usually fine, but when I look at it instrumentally, just from a perspective of how much I’ve actually got done, I’m a little disappointed in myself.
- I’ve decided that I’m okay with it. I’m not trying to any% speedrun my work. I want to be able to enjoy research for what it is, to visit unexpected results and learn what I find intriguing about it.
- A large part of this I think comes down to underestimating just how much I didn’t know about the space to begin with
August 9th
- Finished reading Weaving the Web! Probably my favourite non-fiction read so far this year. Was supposed to just write up quotes but instead wrote a 1.2k word History of the Web piece instead :’)
- It gives me hope!! Trying to change deeply intrenched habits is hard. Getting people to see the potential is hard. But there are so many people working on this and putting their whole hearts and souls into the projects they believe in that I can’t help but believe it’ll work out.
- To quote from Tim Berners-Lee: “When I try to explain the architecture now, I get the same distant look in people’s eyes as I did in 1989, when I tried to explain how global hypertext would work. But I’ve found a few individuals who share the vision; I can see it from the way they gesticulate and talk rapidly.”
- Rough notes on Casper FFG, SBFT. Revising notes on PBFT
August 8th
- I want to target 60 updates per second (~16ms budget) for local and 10 updates per second (~100ms budget) for global updates
- This is a good target to aim for but also wary of premature optimization
- Will likely need to just build stuff out first and experiment to see if it is usable
- Spent some time restructuring all my notes around cryptography to have better note and concept separation
- Reading more about IPFS, their BitSwap protocol for block exchange is a super cool case study on how to do incentive design.
August 5th - 7th
- Went to Hackclub Assemble and was just inspired by the magnitude of talent of the next generation of hackers and builders. Zach (+ Sam and rest of the HC team) really blew it out of the park this time. The theme was to build something completely useless and the kids went wild with it. I still strongly believe that one of the best signals for someone who deeply and intrinsically cares about technology is one who can still play and tinker for the hell of it.
- In a similar vain, I’m organizing a Hack Day at The SF Commons on August 14th! A little callback to my hackathon organizing days :)) Really hoping to bring this new space to life with this event
- Reading Weaving the Web by Tim Berners-Lee. More thoughts on this coming soon, but tldr; it is reassuring to hear that it took almost 13 years to combine the Internet and hypertext together to conceptually create the Web. Even then, it took a lot of trying over many years to bring adoption for something that many didn’t really see as potentially revolutionary
- Reading through PBFT paper, really trying to understand the correctness and liveness proofs
August 4th
- Random thoughts:
- What if messages were doubly-signed with the hash of application source? This would mean that all events are specific to application version.
- Holochain cites that this may be a problem: “unfortunately anyone can modify their own source chain, regenerate the hashes and signatures, and create a perfectly valid, but wrong, alternate history for themselves.”
- However, this is actually a non-issue, given we split this into two cases:
- Single-player App: whatever the user does is ‘correct’ behaviour anyways, what does it mean to have a wrong alternate history when you are the only person dictating it? All actions will still need to be in the domain of valid actions as dictated by the app (otherwise, message signature would not add up as we sign messages with the hash of application source).
- Multi-player App: peers will have a hash of the last known action of a user. If the action history is completely rewritten, the probability of arriving at the same hash is negligible, meaning that the peers will reject any further actions as invalid.
- This brings up a new question of what migration paths look like between old and new versions of applications. If we go by hash of application source, then each update to the source code will seem like a completely new application!
- Each application perhaps can be signed by an author. If a newer application by the same author claims to be an update for the existing application, it can propose an upgrade path to interpret the older data in a usable format for a new one, essentially ‘importing’ the data in
- Good furniture and architectural choices respect user agency, allowing those in the space the ability to move around at will. How might we analogize this to software? Digital commons?
- What if messages were doubly-signed with the hash of application source? This would mean that all events are specific to application version.
- Read through Holochain docs which are actually quite similar to what I have in mind for Rhizome.
- Really liked
- Using RDF triples in a DHT to create a distributed graph database is a smart way to network the data — feels like what semweb was supposed to be
- Everything is self-owned and consistency of application state is maintained by storing hashes of actions to a global DHT which allows for peer accountability
- Things that I think are unaddressed
- Documentation was well-written but the terminology was confusing at times. Was not immediately obvious what part each piece played
- How important is global data-witnessing? Why do we need social pressures for this when we can do this using cryptography?
- This also means that progress cannot be made until a node is back online (otherwise, actions remain unvalidated)
- Problem of getting people to migrate off of existing platforms remains unsolved
- Developer experience is difficult to set up and get started (see HApp setup docs) — heavy use of technical terminology
- Really liked
August 2nd - August 3rd
- Learned a lot about Network theory
- Expanded more on thoughts about the inevitability of centralization with more insights from advantages and disadvantages of scale-free networks compared with random ones
- Also notes on cascading failures, interesting to note that sometimes the most effective way to stop a failure is to prematurely kill edges and nodes (e.g. burning parts of the forest ahead of a forest fire to clear debris in a controlled manner)
- Stressed about what to do for the upcoming gap term/year!!
- Things that are weighing on my mind:
- I want to graduate. Most visas other than the O-1 visa require at minimum a Bachelor’s degree so this is definitely something I’m thinking about. Also, a lot of highly technical jobs are (unfortunately) still gated by degrees so having at least a Bachelors is useful in that regard.
- I want to be able to spend the at least 3-6 hours per day thinking about this research project. I really think that given I have the financial means to pursue research full-time I should. A younger version of me once said that if they found an idea that excites them when they wake up every morning, they would pursue it without fail.
- School Situation: I need 2 more 4xx+ Computer Science Courses and 5 more 3xx+ Electives to graduate. Problem is that it is wayyy past course registration time to jig things around so either:
- I keep my current course schedule (stay on track to graduate next May)
- Unregister from all my courses (push back graduation date to next fall or 2024 May)
- Research Situation: Although the research grant is no-strings attached, I really want to be able to output good work that I am proud of. Plus, the people at Protocol Labs are super cool and I want to be on good working terms with them for potential future collaboration.
- I think summer research has been literature review era and once next semester starts, it will mostly be building things out.
- Other thoughts: in my Letter to my Future Self, I mentioned I wanted to reach deep focus in whatever work I do and have the resources to be able to choose the work I find enjoyable. I’m not going to half-ass do whatever, so it will either be full-send research or full-send finishing school.
- Options
- Keep current class schedule and try to move research to after graduation
- Not nearly as interesting as working on research
- Will graduate on-time in May!!
- Less long-term stress about returning to school to finish things
- I think I’m going to choose this option!!
- Gap year to purely focus on research
- Output research work I am proud of, keep good relations with Protocol Labs
- Keeps research momentum going, will be more effective than picking up the project a year from now
- Will need to go back to school which will feel like I’m set back a year
- Keep current class schedule and try to move research to after graduation
- Things that are weighing on my mind:
August 1st
- Gordon Brander deep-dive today… more thoughts on the inevitability of centralization and credible exit
- It seems we are reaching that ‘recentralization’ step of the decentralization-recentralization cycle, with power concentrating in the infrastructure and application level.
- Gordon proposes abolishing the
same-originpolicy. His thesis is that this forces resources on the web to be centralized around the ownership of domains. Everything — security, privacy, identity, data, and scripting — needs to be provided by the same origin, unless explicitly set otherwise. The ‘hub’ here that everything goes through is the domain. We’ve arrived back at the original centralized hub model of the internet. - How we can learn from the leap that Baran made going from circuit switching to packet switching and apply it to this new layer of the web? In the words of Gordon: “Can we imagine a new weblike thing that is to the web as packet switching is to circuit switching?”
- Gordon proposes abolishing the
- Content-addressing feels like a viable alternative to how loading resources works on the internet today.
- Address-based addressing relies on a central registry to figure out where things are. Content addressed storage (e.g. CIDs) decouples the data from the origin. If you know what the hash is, you can request the original file, irrespective of where the file actually lives.
- There is no single domain hosting your file.
- Many copies of your file exist across the network. This redundancy keeps things safe in case of failure.
- Address-based addressing relies on a central registry to figure out where things are. Content addressed storage (e.g. CIDs) decouples the data from the origin. If you know what the hash is, you can request the original file, irrespective of where the file actually lives.
July
July 30th
- I think I’m going to take a gap semester from September to December to give myself the time to finish the research to a level I’d be happy presenting to Protocol Labs at the end of the year.
- Never thought I’d actually take a gap semester but here I am… looks like I might graduate late now LOL
- I want to spend some time thinking about how to create effective learning and research communities. I know that since I started working in the public hackerspace at Incepto, my productivity has gone up something like 5x. How do I geographically surround myself with people that constantly inspire me to work on ambitious things?
- On a whim, read this awesome Patreon post by Andy Matuschak
- Ben Shneiderman, a pioneering human-computer interaction researcher, offers this charming schematic for research project design in The New ABCs of Research. He calls it the “two parents, three children” pattern.
- I’ve been thinking more about how research seems to come in two layers
- The ideas
- The language in which it is expressed
- Majority of my time has been on refining 1. so that 2. may come easier, but perhaps both should be worked on in concert.
- I’ve been thinking more about how research seems to come in two layers
- Ben Shneiderman, a pioneering human-computer interaction researcher, offers this charming schematic for research project design in The New ABCs of Research. He calls it the “two parents, three children” pattern.
July 24th - 29th
- Roadtrip! Had a really fun roadtrip with Anson, Joss, and Jaclyn from SF to LA. Stopped at a million beaches, observed some stunning sunsets, surfed for the first time, ate great food, and sang lots of songs. Learned about ‘Surfboard’ by Cody Simpson which was the trip themesong.
- On July 25th, I heard back from Protocol Labs and got my first large grant for 20k for the next 4 months!!!
- I think this support will mean a lot for the project. Protocol Labs is incredibly values aligned and they have some of the brightest minds thinking about similar problems. Even just being in an environment where I know I can expect feedback from these people (not to mention financial support) feels like a major milestone
- I really loved how they have an RFP-000 which is an ‘open-call’ for research that may not fall any other current category
- They are strongly encourage I have more ‘traditional’ research outputs, which I think makes a lot of sense! This will give me more exposure to the more ‘academic’ side of research as
- An open-access paper or brief technical report (e.g. submitted to arXiv)
- An open-source code library with good documentation
- A recorded, shareable presentation of the work, preferably as part of our research talk series (!! this is really exciting).
- A blog post describing the impact of your work to be featured it their research blog.
- An open-access paper or brief technical report (e.g. submitted to arXiv)
- I especially love how the grant is ‘no-strings attached’. I think this really incentivizes honest behaviour and reporting of true outcomes rather than encouraging fabricated results or demos to get funding.
- “Unsuccessful projects. Our interest is in accelerating science for the benefit of all. Naturally, over time we will be more likely to fund proposals from active and effective members of our community. However, we understand the complexities of research and do not revoke payment if the work changes course, is unsuccessful, or reaches a dead end. We value great results but also understand the value of exploration and impossibility results.”
- My passport is about to expire so I will need to be in Canada for fall :(
July 22nd - 23rd
- Finished up the identity piece! Cent and B from Metagov gave some very good advice and clarifying feedback on the piece.
- I think the essay was trying to do too much so I’m going to split out the content and keep all the stuff about agency and legibility in this one.
- I want to write another piece eventually about different ways of being online (specifically, collective inter-being vs individualism)
- The new atom of identity is not a single entity but a set of relationships. A group chat. A chat that isn’t just a text messaging history but can embed applications and rich worlds on top of it.
- Elaborate more on groupchat as an entity
- I have a bunch of reading piled up this week since I’ve been doing a lot of writing so I’ll focus on getting through some more stuff today and tomorrow.
July 21st
- Polishing up identity piece. I’ve worked on it enough that I’m starting to feel ick just touching it but I’m happy that I’ve thought about this deeply. Implications for Rhizome as a whole:
- Self-sovereignty seems useful for agency if implemented in ways that don’t force legibility
- e.g. be careful about VCs without zkSNARKS
- Probably will need to think more heavily about how to model a relation history on the dev side of things as people are used to modelling individual users. Perhaps phrasing the basic item as a group chat makes sense?
- Self-sovereignty seems useful for agency if implemented in ways that don’t force legibility
July 20th
- Finally got the piece to a place where it is ready for feedback. B, Shrey, and Saffron took a look and left a bunch of comments which identified plenty of spots where either my reasoning was flawed or just wasn’t good.
- Revision time !! 🙃
- Feel like I haven’t been very proactive in thinking about funder relations.
- Found out today that GitHub has a very handy feature to email all of your sponsors!
- Will probably draft up a short update email and include a link to the identity piece as soon as it’s done.
July 19th
- Slowly reaching a place where I’m happy with the direction of this piece on identity, framing it more around 3 modes of thinking about identity.
- Got a comment from Zoë Ruha Bell on my essay in Reboot that asked about “the complexities of how moving data between contexts changes its meaning and that individual control over data may not match up well with the relational information encoded in data”
- Incidentally, this is exactly what I’ve been thinking more about! My response:
- This is a great question and I’m still grappling with (and in the midst of writing a whole other piece about!). Data in context is incredibly important. Like identity, when taken out of context, it can be incredibly harmful and misused. Pursuing interoperability without considering the intention behind the actions that data encodes can easily turn dangerous very quickly.
- One way I’m thinking about this is analogizing the multiple facets and contexts of data as people. Just as people behave differently in different contexts, so can data. The same reason we have so many ‘alts’ or ‘finstas’ is that this multifaceted-ness isn’t accommodated by existing media platforms. Data platforms similarly treat data as single faceted. What does a multi-faceted encoding of data look like? What does communal ownership of data look like?
July 18th
- I’ve been trying to write down some more cohesive thoughts around identity for the past two days and running into a block where I’m struggling to articulate why and how real world identity and digital identity differ
- Just read this blog post on Going Doorless that really resonated and gave new language to ideas and concepts that have been floating around in my head for a while
- Public commons like parks and libraries feel public because moving around in them is effortless
- We don’t have commons because the space between digital spaces have the viscosity of honey. Movement becomes heavily disincentivized.
- To be clear: I mean that people should be able to move freely. Data should have access control switches exposed to users. They should decide whether it moves freely or not. “after voluntary communication to others, free as the air to common use”
- You shouldn’t need to pay or set up and account to walk through the gates, commons just let you show up and start using it
- Software is the principles of an experience, your data is just the details
- Public commons like parks and libraries feel public because moving around in them is effortless
July 16th - 17th
- Currently on a two-day writing retreat with Belinda, Athena, and Vincent. It’s been such a good mix of sight-seeing and focused writing.
- The other choice of spending this weekend was to go to an Art Book Fair and assemble furniture with friends. In all honesty, I’m very glad I chose to focus and write over just socializing.
- Some good time away from purely technical reading meant I had time to think more about identity. More thoughts around verb based identity
July 15th
- Part of the nail of my left pinkie ripped off today argH it is now painful to type :((
- Realized that when doing site redesign, I lost a commit’s worth of notes (sad) but also Obsidian Sync which I normally use for backup also expired today (double sad). Not as bad as it could have been though! Thankfully I commit often :)
- Spent a lot of time just reading today, a lot of different scattered blogs that I’ve been meaning to get to. One link that was sent in the Metagov Slack particularly stood out to me though. It was on human identity and, more specifically, a critique of specifically SSI
- Long read but I think it captures a lot of my thinking around why I think digital permanence is scary (and why I’ve been thinking about relational notions of identity!) TLDR;
- The concept of identity is very noun-like (i.e. tied to physical traits and current state) in Computer Science + software systems
- Contrasts with identity as verb-like (i.e. incredibly contextual, based on who you are with, how you are feeling, what experiences you have)
- “The joins are the pathways for information exchange and transformation, for organising, and the expansion of organisational identity. Joins give the dots their meaning, their contextual relevance, their identity, just as dots give the information exchange direction and potency.”
- Long read but I think it captures a lot of my thinking around why I think digital permanence is scary (and why I’ve been thinking about relational notions of identity!) TLDR;
July 14th
- Reboot published my research proposal / manifesto / essay on Rhizome and data-neutrality today!
- Check it out on Substack
- Ben Tarnoff, the guy who cofounded Logic, actually read and tweeted about it and readers seemed to resonate a lot with the post!
- Two general sentiments:
- This project seems really exciting and I appreciate it recognizes existing work. What will get people to use this though? The social difficulty with “apps as a view over data” is that it requires users to understand data models and this consensus over data models has proven difficult
- I agree with this evaluation and so far, feels unsolved. I think a promising solution is to think about it like how community-sourced types for TypeScript work. There’s a whole open-source project that wildly popular that provides TypeScript definitions for plain JS libraries called DefinitelyTyped (with over 12.6 million usages!). I think there’s a potential for this to work with data schemas as well
- Well.. crypto/existing-thing actually solves this! Blockchain scaling techniques are getting pretty good, don’t see why this work is necessary.
- Again, true. I think these new technologies all seem really promising and I definitely try to keep up with all the developments in the space but my main concern comes from how convoluted these solutions are slowly getting.
- A lott of smart people in crypto have been working on these problems for a while, I’m starting to think it might be easier to tackle it from the other side. Plurality of approaches y’know :))
- This project seems really exciting and I appreciate it recognizes existing work. What will get people to use this though? The social difficulty with “apps as a view over data” is that it requires users to understand data models and this consensus over data models has proven difficult
- nobody: … youtube: https://www.youtube.com/watch?v=g7MSfHEdxXs
- Going to read more about causal trees as a way of understanding more basic forms of CRDTs that value readability over correctness
July 13th
- Feeling a little tired of just reading papers and coding
- Going to do a mental reset and just play piano for a while and then doing that person website redesign that I’ve been thinking about for a while now…
- Update: this is so fun gah
- Realized that the typography on the old site was kind of garbage and hard to read. Spent a bit of time reading up on good typography practices and it looks soooo much better
July 12th
- Ok, a bit of a wrench in the system : ’ )))) CRDTs are incredibly hard to reason with for the average dev and cannot guarantee global invariants without requiring consensus.
- Finished up CRDT implementation collection over at CRDT Implementations.. I feel like I’m getting a better grasp at how to write op-based CRDTs but less so for state-based
July 11th
- Seems like there are a lot of open research questions in CRDTs that I could plausibly spend years working on (e.g. undo operations in CRDTs, encrypted CRDTs using homomorphic encryption)
- I need to read more about this but it seems like most traditional consensus algorithms require synchronicity from all nodes for them to be considered honest. I wonder how we can reconcile this methods like CRDTs that allow for more asynchronous forms of consistency
- Is it possible to take advantage of the partially synchronous system model and having CRDT-like behaviour in async modes and Raft/Paxos-like behaviour during synchronous periods for compaction
- This is especially important as users will rarely have all (or even supermajority) of their nodes online at any given time. Will need to look into variations on Raft that tolerate live membership changes
- “The network can partition and recover, and nodes can operate in disconnected mode for some time.”
July 10th
- A lot of good meditations on adoption of tech that gives agency to users at a Hack Night that Rishi hosted :))
- Currently at another session of the writing circle. Good to probably zoom out from a lot of the technical in-the-weeds work and re-orient about what this means for the average consumer
- Do people care about data ownership and data agency?
- The average user probably doesn’t. They want convenience and are comfortable with current options.
- But as a counterpoint, if you ask anyone on the street whether they would be comfortable sharing their entire browsing history right there on the spot, my bet is that ~95% of people will say no
- This could be a really fun social experiment: incrementally increase the amount you offer strangers to look at their browsing history
- How much does the average person value their privacy?
- Yes, companies and the government have a lot of data/info on us
- But what has come out of it? For the average consumer, nothing! There is a definitely anxiety of but what if with no real bad cases (that we know of)
- Another question is why having a real person snoop on your data feels so different than large companies snooping and profiting off of your data
- I suspect a large part of this is due to learned helplessness
- We haven’t ever really known what it is like for companies not to be doing that
- It feels abstract! A company remotely snooping on your data is something that a user could remain fully blissfully ignorant from
- I think people don’t care because they haven’t known what a possible future could look like
- People don’t ask for cars because all they’ve known in their lives are horses. They can only think of faster horses
- How do we convince the average consumer that this is something worth caring about?
- Near zero-friction doesn’t necessarily people will want to switch to this new paradigm. It is still a non-neglible activation energy to move platforms
- This probably won’t happen unless there is both 1) a radical push away from existing centralized platforms and 2) a strong and convincing pull towards new decentralized platforms like Rhizome
- This is where I think regulation, anti-trust, and legal requirements for data usage transparency are incredibly important! There are institutions just as powerful as these large tech companies that can serve as a counterbalancing force too
- This still feels incredibly difficult as these tech companies have started invading these regulatory bodies and holding immense lobbying power
- We do so by providing tangible and real improvements over existing products (that matter to the average consumer)
- Never need to manage a million different accounts again
- Local-first feels lighter and faster
- Easily understandable ToS (people know what access are giving away)
- End-user programming should be trivial and non-technical (i.e. making integrations like Zapier useless)
- This is where I think regulation, anti-trust, and legal requirements for data usage transparency are incredibly important! There are institutions just as powerful as these large tech companies that can serve as a counterbalancing force too
- Why would companies care about this model of computing?
- tldr; building and maintaining a data moat is hard
- Computation happens almost entirely on end-user devices, need to host massive infrastructure goes way down (unless you are doing heavy ML and info processing, which most companies are not)
- New markets for lending compute to the masses rather than just to programmers and tech companies
- Almost all the grunt work of data transformations is eliminated so companies can focus on business logic
- GDPR compliance built-in, users have freedom to manage their own data
- Meta-meditations: this was incredibly helpful to iron out philosophy a bit more. I think this is starting to make more sense from both a user and company perspective, but only for people who care about these sorts of things. I think end-game is getting my Mom to understand why this is important.
July 9th
- Various notes on CRDTs
- Seem to require consensus for state compaction
- Learning about HLCs and maintaining causal order in CRDTs
July 8th
- Learning more about CRDTs, Order Theory
- I got my first email from a mutual which was along the lines of “help, I’m stuck in leetcode hell, how do I escape and do other things?”
- I feel like I barely know what I’m doing, let alone ready to help another person along on their journey! I sent along a few questions that were really helpful for me when convincing myself to do this project and I hope it’s useful.
- Here was the email response I sent:
- Had a great chat with Saffron today about some of the really cool research she’s thinking about doing re: online identity and data agency.
- This really would not have happened if Spencer hadn’t pushed me to write a thread briefly summarizing what I was working on this summer. I’ve had a lot of super cool folks reach out and say that they are really excited by the work I’m doing! This is both reassuring but also extremely nerve-wracking. Expectations!!!! A concept
- One point we talked about that I’m still ruminating on is the idea that selling data requires a baseline level of interoperability between two parties
- How do current data markets work? If Facebook for example sells their data to another company, is it literally a raw export? How does that handoff happen and how do they ensure the format of the data they are using is understandable by both parties?
- I think inspiring more thoughts on what potential business models could exist on a platform like this
July 7th
- Finished up Tim Roughgarden’s lectures on the foundations of blockchain which had some really useful theoretical details on traditional consensus mechanisms which definitely solidified my understanding
- Currently at ~$900/mo in terms of sponsors and I’m just blown away by the volume of support people have expressed. This is more than halfway to monthly living expenses and it feels so close?
- At first I was a little nervous because, y’know, that’s a lot of expectation of producing something meaningful
- But I think this is exactly the forcing function I need to be active in doing as much as I feasibly can and share as much as possible. Even if someone steals my idea and runs with it, so what? The future is pluralistic. If it’s interoperable, it doesn’t matter how many implementations there are!
- Read a really good paper on neutrality and learned about the Data Transfer Project
July 6th
- Holy shit Morgan, Aadil, David, and JZ just sponsored me for ~$400/mo for this research project and … I am genuinely just speechless??
- It’s just so wild to me that this little project that I’ve just felt so strongly about because of reasons that still seem to evade words is something that other people are interested in seeing come to life too.
- It feels like this project is a mountain I’ve set my sights on hiking for the longest time. And for a while I was hiking it alone, appreciating the scenery and the path but the path was lonely. But now I can hear the singing and laughing of my friends as people cheer and join along for the journey and it feels just a bit more manageable.
- The generosity of these friends (shoutout to MFC and Anson) means that paying the next two months of rent and food isn’t something constantly nagging at the back of my mind :’)
- There were many points this summer I was fully ready to give up (see: plenty of mental breakdowns below) and stop trying because I questioned whether this was worth doing — if I should just stop and get an actual job
- I felt really silly for asking people to help financially on a project that I sometimes had trouble believing in too.
- So thank you for your trust, thank you for dreaming with me
- Today’s soundtrack is from La La Land — Audition (The Fools Who Dream)

July 5th
- Finalizing notes on Tendermint and wondering if I should switch out Raft for it. How valuable is BFT anyways? Do we assume nodes are prone to potentially malicious takeover?
July 2-4th
- An ‘aha’ moment caught in 4k… watch me try to figure out why asynchronous and partially synchronous system models aren’t the same thing (s/o Sebastien for being so kind and patient). This was super satisfying!
July 1st
- Internet went out today halfway through watching lectures :((
- Spent a bunch of time just reading books + thinking
- More notes from Tim Roughgarden’s foundation course on PKI, BB, impossibility theorems, etc.
June
June 30th
- Settling into a better work rhythm I think.
- Food here is surprisingly expensive but groceries is still miles cheaper than just getting Uber Eats everyday.
- Have a sudden urge to work on my personal site but I will ignore that for the time being…
- Sebastien sent a YouTube playlist on the foundations of blockchains that have some sections which seem highly relevant. Slowly making my way through these
June 29th
- Finally wrapped up school! Anson is headed back to Arizona today too :((
- Living together has been a fun dance of trying to balance our energy levels, but felt very much like a team throughout. I’m really glad I chose to prioritize relationship, truly some moments over the past month where I was like “wow, is this real.” It feels like I’m selectively giving deep attention in-turn to the things I care most about.
- Now is the era to just fully focus my attention on research and this project though
- I think this finally means that the vast majority of my waking hours will be on research. Uninstalled a game I was spending way too much time playing :’)’ it is grind time
June 27-28th
- Nearing the end of my literature review era. Still need to go through Braid/Redwood, SSB, Yjs, and Hypercore inner-workings.
- Thinking it might be good to do a general overview of CRDTs before delving any further
June 26th
- Belinda and Athena from Incepto told me about an SF writer event which happens every week and I’m currently at it right now. So many people here are just working on such really cool things and I’m excited to potentially have this space as incredibly condensed resesarch + thinking time. I think this is a great forcing function every Sunday to just… orient myself for the week and get shit done.
- Talked with some really really cool people at a birthday party in SF which were surprisingly receptive and interested in my work. Will definitely follow up on these conversations.
- More research on CouchDB and other database replication mechanisms to see what I can learn from it
June 25th
- HackLodge meetup today, also met up with Spencer and Liam. Talked lots about the project then realized I haven’t spent much time just… sitting down and grinding out work.
- A decent chunk of it is 1) summer courses taking up much more time than I expected them to and 2) wanting to meet people in SF and spend time with Anson while she is still in SF… priorities priorities
- To borrow words from Anson, it’s “hermit time”. I feel like I am definitely behind schedule in terms of what I wanted to get done by this point of summer and I need to put in some serious work and thinking into this project.
June 24th
- Reading about Hyper Hyper Space, doesn’t seem to place a big deal of emphasis on finality which seems important for a large chunk of applications.
- Open questions:
- Append-only log or append-only Merkle-DAG? Leaning more towards log still for easy understandability + debug even though Merkle-DAGs are more expressive (and battletested in blockchains and
git)
- Append-only log or append-only Merkle-DAG? Leaning more towards log still for easy understandability + debug even though Merkle-DAGs are more expressive (and battletested in blockchains and
June 20th - 23rd
- Reading about VDFS’s (specifically Alluxio) and
- Open Questions
- Handling cases where data > storage availability
- Checkpoint heuristics: when to checkpoint? especially important if Rhizome is to run indefinitely
- “Lineage chains can grow very long in a long-running system like Alluxio, therefore the checkpointing algorithm should provide a bound on how long it takes to recompute data in the case of failures”
- Settling into new place, we cleaned out the garage (which is where I am staying) and made it somewhat liveable?? Took a lot of work, the previous tenant didn’t even properly move out which was a stressor for a little while
- Because there is no proper heating/cooling, sometimes I literally work with the garage door open for good circulation which gets me weird looks from the neighbours but it’s fun
- Incepto people have all been super nice and they are all working on/exploring cool things. I get a little distracted sometimes just working in the garage so it’s really nice I can just hop over to the hackerspace in the house to get some more focused work done.
June 16 - 19th
- Interact Retreat! Lots of good conversations about the work I’m doing which has been super clarifying for what type of explanation gets through to certain types of people
- Generally find framing it in terms of net neutrality but applied to data gets a lot of people excited about it, as well as meaningfully explaining + differentiating from Tim Berners-Lee’s Solid project and how Rhizome focuses on addressing main retro points from major p2p protocols.
June 14 - 15th
- Mostly trying to answer questions around how decentralized marketplaces for demand work, looking at Golem and Orchid
- Lots of moving around (moved from Tempe to SF, about to head to Interact retreat!)
June 13th
- Rough research notes and open questions on DWNs
- DID document needs to specify the service
- Resolve a DID to web node URI
did:example:123→ resolve to Decentralized Web Node endpoint(s) →https://dwn.example.com
- Raw vs Signed Data
- Raw → only data + descriptor
- Signed → data + descriptor + attestation (JSON web signature/JWS)
- more details: https://identity.foundation/decentralized-web-node/spec/#message-descriptors
- Storing data relative to a schema
- https://identity.foundation/decentralized-web-node/spec/#query
- schema field in descriptor
- JSON-LD + https://schema.org ?
- or… openzepellin style, vetted schemas
- data lensing should fit into this
- Permissions request
- https://identity.foundation/decentralized-web-node/spec/#request
- signed message
- define scope
- based on DAG commit range perhaps?
- Potentially using UCANs
- Open questions
- How does DID ownership work? what is it pinned to? is IPFS sufficient?
- TLDR; DID needs to be generally anchored to something. Notes on Sidetree, a backend agnostic DID persistence mechanism
- How do we make ownership/data management easy for non-technical people?
- How does DID ownership work? what is it pinned to? is IPFS sufficient?
June 11-12th
- Roadtrip with Anson! Much needed break to get a mental break and reset
June 10th
- Spicy day today… Jack Dorsey just announced TBD working on Web5, supposedly an extra decentralized web platform (https://twitter.com/jack/status/1535314738078486533)
- Feel like a little boat in a big ocean where huge battleships drift by every now and then
- Makes me doubt what I can really do as this small little boat
- But reminded that steering my own little boat gives me agency as to what I can explore and do
- The little boat that could
June 9th
- Lots of research, mostly around FOAF, LDP, RDF
- Looked more into decentralized marketplaces like Raiden and Orchid to see how they handle payments
- Mostly just reading articles and specifications, your average day of research
June 8th
- Got my first grant rejection from Emergent Ventures today :((
- Feeling.. kinda numb? I feel like grand scheme of things it doesn’t matter but this is the first hard no that I’ve gotten
- Spent some time looking for some other grants but my conclusion is that I should spend more time getting shit done before asking for more funding.
- I have enough in savings to last me until end of summer but it means I’ll have to start contracting during the school year which isn’t ideal, but gives me pure focused time this summer to just do research.
- Onwards!
- Lots of really great bits from Browser Co’s piece on Optimizing for Feelings
- “Anything new is by nature without precedent — meaning, without data to know whether it will work or not. So when we approach building new things, we don’t optimize for metrics. We optimize for feelings”
- “How do you feel when you finally step foot in your own living room, after weeks away from home? When you plop down on your own bed, or whip up a meal in your own kitchen? It conjures up a specific feeling, doesn’t it? That’s because these spaces are a reflection of you — created by you, for you. Software can feel the same way if individuals have agency and sovereignty over what is on their screens.”
June 4th - June 7th
- Getting back into a working groove after moving again, Arizona is ridiculously hot. Made the dumb mistake of walking to the grocery instead of taking transit lol
- Learned more about underlying datastructures of IPFS including CIDs
- Potential for interop between IPFS and DID Documents?
- More notes on DHTs and Kademlia in particular
June 1st - June 3rd
- Had a call with a few others folks working adjacent to decentralized infrastructure and people seemed pretty excited about the proposal! It was the first time in the past month that I felt pretty confident about the project when talking about this with others, definitely a personal milestone :)
May
May 28th - May 29th
- Attending friends’ graduation for the past few days, crazy to think that this will be the last time I see some of these friends for a long time.
- Worked on thinking about and polishing my grant proposal, finally getting to some phrasings that resonate and sound good
May 27th
- Finishing up
miniraft, added tests for voting and fixed up some workflow stuff to auto-test and publish documentation!!! It’s published now on GitHub :)) - Notes on DID which seems particularly applicable to the notion of identity + identity documents
- Once again had a breakdown :)) Constantly feel like I’m not doing enough and that time is slipping between my fingertips…
May 23rd - May 26th
- Catching up on school work
- More reading + notes in decentralization, authorization, and federation. Notable readings:
May 21st - May 22nd
- Packing + flights! I am now in Vancouver for the next week :))
- Hectic flying experience… didn’t get much done
May 20th
- Chatted with Justin Glibert who gave some very piercing advice
- What is the most you can cut from your current proposal and have it still be meaningful?
- via negativa: essentially the study of what not to do
- In action, it is a recipe for what to avoid, what not to do—subtraction, not addition.
- You can’t know what is going to work but also you know there are things that are obviously not.
- Don’t try to think you are a god and reinvent everything from scratch. Don’t catch NIH syndrome.
- via negativa: essentially the study of what not to do
- You only have 10 beautiful idea tokens in your life you want to do it so you should just do it
- Don’t just do the plumbing and make stuff you already are good at if you’re trying to learn
- If this is something you just want to work on (true in this case) then work on it with your full heart
- Not being harsh because it’s a bad idea
- But rather I don’t want you to waste your time. This is your last summer without ‘real-world’ responsibilities. I would trade so much to be in your position right now.
- I am being harsh so that you spend your time wisely and don’t do something stupid.
- What is the most you can cut from your current proposal and have it still be meaningful?
- Technical thoughts
- Is Rhizome actually a generalized form of state channels?
- EVM + Solidity on top of little chains between people
- Minecraft on top of this to build engines like https://www.worldql.com/
- Is Rhizome actually a generalized form of state channels?
May 19th
- Proposal re-writes + more research today, got a lot done in office today and still had time to head to Central Park to read… a great day all things considered.
- Open questions from today’s reading + writing:
- How do identity ‘clusters’ or organizations/groups of people work? How are they represented?
- Perhaps instead of having separate instantiation of your identity on fixed set of apps, we can have the same identity with separate instantiations of the app?
- Who runs cloud peers?
- Have a global marketplace where people can list/sell spare compute and storage
- Who does the compute?
- Most apps are lightweight to run on people’s own devices
- The main reason we’ve needed massive datastores and compute centers in the first place is because large companies have centralized billions of people’s data into their own servers
- Cloud peers can offload and perform heavy lifting if necessary
- How do identity ‘clusters’ or organizations/groups of people work? How are they represented?
- More meditations on identity and data
- Thinking about how data exists only as relations between things… how do we preserve this?
- ‘Data’ is data in the context of that user (or group of users) using that specific application
- Learned about the concept of petnames in more depth today and there’s a really cool way of thinking about identity here perhaps
- Almost all of the contexts in which we collaborate are not global. The you I know is likely different from the you your family knows. Identity should be relational rather than standalone?
May 18th
- Grant writing + Verses proposal wrangling
- Had Anson tear apart my proposal today
- It was so incredibly helpful to get that level of honest feedback but I just feel in the dumps right now LOL I need to figure out how to untie my own self-worth from my work
- I expect something similar will happen when I meet with Justin.. and many more times this summer
- Good feedback is equal parts bitter and sweet
- Bitter in that it tells you the harsh truths that few have the courage to
- Sweet in that they truly care enough and have enough faith to point harsh truths out
- “When you’re screwing up and nobody says anything to you anymore that means they’ve given up on you…you may not want to hear it but your critics are often the ones telling you they still love you and care about you and want to make you better.” ― Randy Pausch, The Last Lecture
May 17th
- Went to NYC to work at the Thrive Capital office with some Interact folks and wow… the difference being outside and in a good working environment makes is ridiculous.
- Migrated all the tracing stuff out of
server.rsandlog.rsinto its own file. Makes the code a lot cleaner to work with. - Deleted
transport.rs(and moved the contents intotests/common.rs) now that it is no longer a part of the server. Realizing now I’ll probably need to do another refactor of the transport layer to support simulating network partitions, dropping packets, etc. so I have more surface area to test with. - Talked with Sebastien who has been doing independent research for almost a decade now. Mentioned that I was really feeling like I was in the depths of the Valley of Despair and he just laughed and said “that was me 10 years ago and I still feel that way.” Horrifying but also weirdly comforting? He gave me some advice and thoughts (mostly with regards to independent research but honestly a lot of sage life advice too) which I wrote down in this page on independent research
- To be honest, I don’t really understand all of this advice yet and I don’t pretend to but at the moment, it gives me comfort that even if there isn’t light at the end of the tunnel, the darkness will still be enjoyable
May 16th
- Grant writing again… Finished rough draft for Protocol Labs RFP 000 and writing EV grant proposal + getting feedback
- Had a mini-breakdown today after realizing I am just not enjoying this as much as I thought I would be. I’m often spending 12+ hour days writing code or grants and I just feel so behind. And I don’t get why!!!! I’ve been looking forward to this summer for so long.
- I think financial uncertainty is becoming more real day after day… really hoping that one of these goes through and is successful
- It’s too early to quit. There’s still so much more to build/learn/do/write and I’m not ready to throw in the towel just yet.
May 15th
- Family roadtrip, no work today :)
May 14th
- Finish testing harness - it looks so pretty!
- Finally updating research proposals after putting it off for 3 days. I suspect I’m using
miniraftas an excuse to avoid the grant writing because making things legible is hard!! I’d much rather write code and look at pretty command line outputs instead but this is important work that needs to be done.
May 12th - May 13th
- Reaffirming myself that a lot of this is necessary learning and this is a worthwhile project
- Not sure if this is actually true
- But more so convincing myself of it so that I have the energy/motivation to go through with it
- A lot of technical refactoring going on to accommodate unit testing
- Removed a lot of unnecessary lifetimes while changing
RaftServerfunctions to return a vector of sendable messages rather than directly having each server hold a mutable reference to the transport layer (Rust doesn’t allow multiple mutable references without aRefCell!)
- Removed a lot of unnecessary lifetimes while changing
Let’s say you want to become good at [x].
It’s almost impossible to do it because every day on Twitter you have friends who’ve raised 6 million to do crazy stuff. And so every single day, you open your books, and you take your notes and you start writing stuff, and you have to solve those equations.
And every single day you tell yourself, why am I doing this?
I could just go out and bullshit investors and build a company. And I think too many people actually do that. Myself included. I managed to resist for a while and I spent a lot of time learning different, difficult things, but it’s very hard not to have ADD in this world. It’s very hard to stay focused on important things that take a while to be learned.
May 11th
- Finished the first pass of implementation of
miniraft! In the midst of adding test infrastructure and verifying correctness of the implementation.- Probably spent tooo long making it look nice but hey, if I’m going to be spending hours looking at this it might as well be good to look at
- Also spent an hour trying to debug a test only before realizing
cargo testruns in parallel so debug messages were out of whack - Feeling quite demotivated regarding overall self-belief in the project even though I’m only 11 days in! Been trying to explain Rhizome to a few folks who have experience in the space and it is often so intimidating.
- Like yeah, I know this probably isn’t the best way to go about it. Maybe they’ll tell me what I’m working on is a long solved problem and I’m wasting my time. Or “couldn’t you just use x and y to achieve the same effect”? I can’t help but sometimes feel like I’m wasting my time — there are so many smart people working on the same problem, what makes me feel like I can be the one to make a meaningful contribution to it?
- I know that regardless of whether this project succeeds a lot, I’m already learning a lot in terms of technical skills and also about myself in the face of uncertainty and more independent work so I will take that as a win regardless.
May 10th
- Discussing grant proposals with Verses folks, doing a lot more grant/proposal writing than I’d like these days
- Finished most of
miniraftlogic up untilcommit_log_entries. Still need to add tests though :’) - Tech bear market isn’t promising for raising funding, esp for more experimental/greenfield work like this :((
May 9th
- Literally just wrestling with Rust’s borrow checker because
dyntraits are funky :((- Ran into a really weird design problem where I wasn’t sure how to order the lifetimes of the log or the state machine (should the app own the log which owns the state machine? should the log hold a reference to the app)?
- I opted to construct the application first then pass a pointer to the log so that when appending entries to the log, it can just call
self.entries.iter().for_each(|entry| self.app.transition_fn(entry))
- Finally caved and watched an hour long video on closures,
Fn,FnOnce,FnMut, boxed closures, and function pointers (Jon Gjengset, I owe you my life)- Feels really stupid but it was literally a change from
&'s mut dyn App<'s, T, S>toBox<dyn App<T, S> - When lifetimes get as messy as they did, there’s probably a cleaner way to do it with a heap allocated value :)) Use
Boxmore often!
- Feels really stupid but it was literally a change from
May 8th
- Sketching out grant proposals to Emergent Ventures + Protocol Labs
- Had a chat with Sebastien about research institutes and what long-term support for work like this could look like in the context of Verses
- More implementation work for
miniraft, about halfway done I think?
May 7th
- Does not seem promising that my research work will be support by Verses this summer…
- Looking for other places to apply for funding but ugh this is unfortunate
- Lots of coding today for
miniraft! Finally feeling like I’m becoming more fluent in Rust. Figured out some nasty named lifetime stuff today by drawing a few diagrams and kinda feel like a wizard!!! Small wins
May 6th
- Mostly writing up recent learnings and incorporating them into the research proposal… lots of words today
- Sometimes I feel like I’m doing research to be able to do more research…
- I think I am finally getting to a point where Rhizome is making more and more sense and obvious why it is necessary
- I started this project/research very much like “oh wow, this is a cool set of technologies and here are some vague words and feelings about what I think is inadequate in the space” and it has sort of refined itself into a clear use case!
- Came across the concept of a “cloud peer” today in Hypercore documentation and it was like “WOW I had this exact same idea and they already have a name for it” and it was so cool
- Really excited about this future of ‘personal cloud computing’
- I think this summer will be mostly focused on the data replication / identity aspect of Rhizome, realizing that I think I was way too ambitious with my first proposal
- More implementation on
miniraft. Rust feels so slow to get back into a ‘de-rusted state’ (hah) where code just ‘flows’. It feels fun though! Type system reminds me a lot of Haskell.
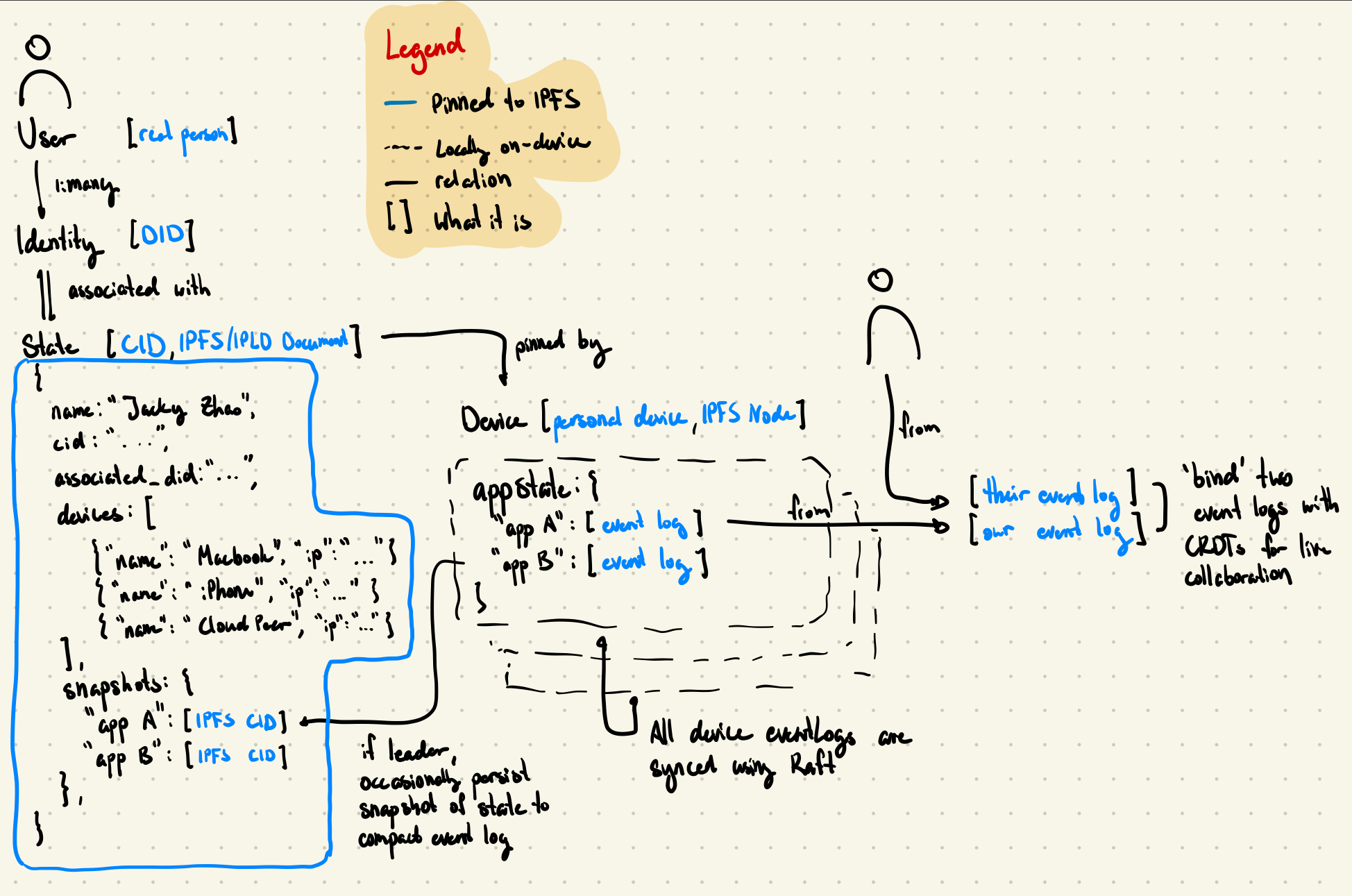
May 5th
- Finishing up Martin Kleppmann’s Course on Distributed Systems
- Cleaning up notes into atomic concepts that I can reference
- Continuing implementation of
miniraft - What if… Rhizome had built in mechanisms for managing ‘branches’
- Default branches are single stream
- To make a collaborative doc you can ‘fuse’ or ‘join’ branches together temporarily to sync them with each other
- What if we made something on top of
gitlike this that actually functions on a syntax level rather than a character level… one for the idea list
- What if we made something on top of
- Pace layers for collaboration
- Real-time (keystroke-by-keystroke)
- On-click (manually click refresh)
- Suggest changes (like Google Docs, accept/reject)
- Agreeing on what operations a CRDT can perform still seems to be difficult (see 1hr into this talk)
- Possible room for data lensing on public schemas to be useful here
May 4th
- Skimming Martin Kleppmann’s Course on Distributed Systems
- Really good foundation to work off of
- Learned about differences between physical and logical clocks and realizing that
miniraftshould probably use some sort of logical clock rate
May 3rd
- Read about more NAT traversal and holepunching efficacy, turns out hole punching is just not as reliable as I thought it was
- Compared more traditional consensus algorithms like Raft to Solana.
- First formal architecture sketch?
- Need to read more about DID and IPFS but this seems like a promising start?
- Each user is essentially a DID that is associated with an IPFS document that references a bunch of other things
- Each device in the devices array runs a Rhizome Node which is essentially a wrapped IPFS node that pins the user IPFS object and can edit it
- Right now, this means that if all a user’s devices are offline, those files are unreachable. For people who still want their stuff to be replicated online, perhaps can integrate FileCoin to incentivize other nodes to pin their document?
- The devices array is also used by Raft to coordinate what devices should be included in the cluster
- Modifications in the devices array leads to a Raft configuration update
- All devices that are reachable sync via Raft to keep an
appStateobject up to date for the user - When any
appStatelog gets too long, it is snapshotted by the leader and persisted in IPFS.
- All the questions that are unanswered right now are in red. Lots of unanswered questions :))
- How does auth work for applications?
- How will schemas be published? Is there an app store?
- Who runs the web host? Is it self-hosted?
- What about non-technical people?
- How is a user created?
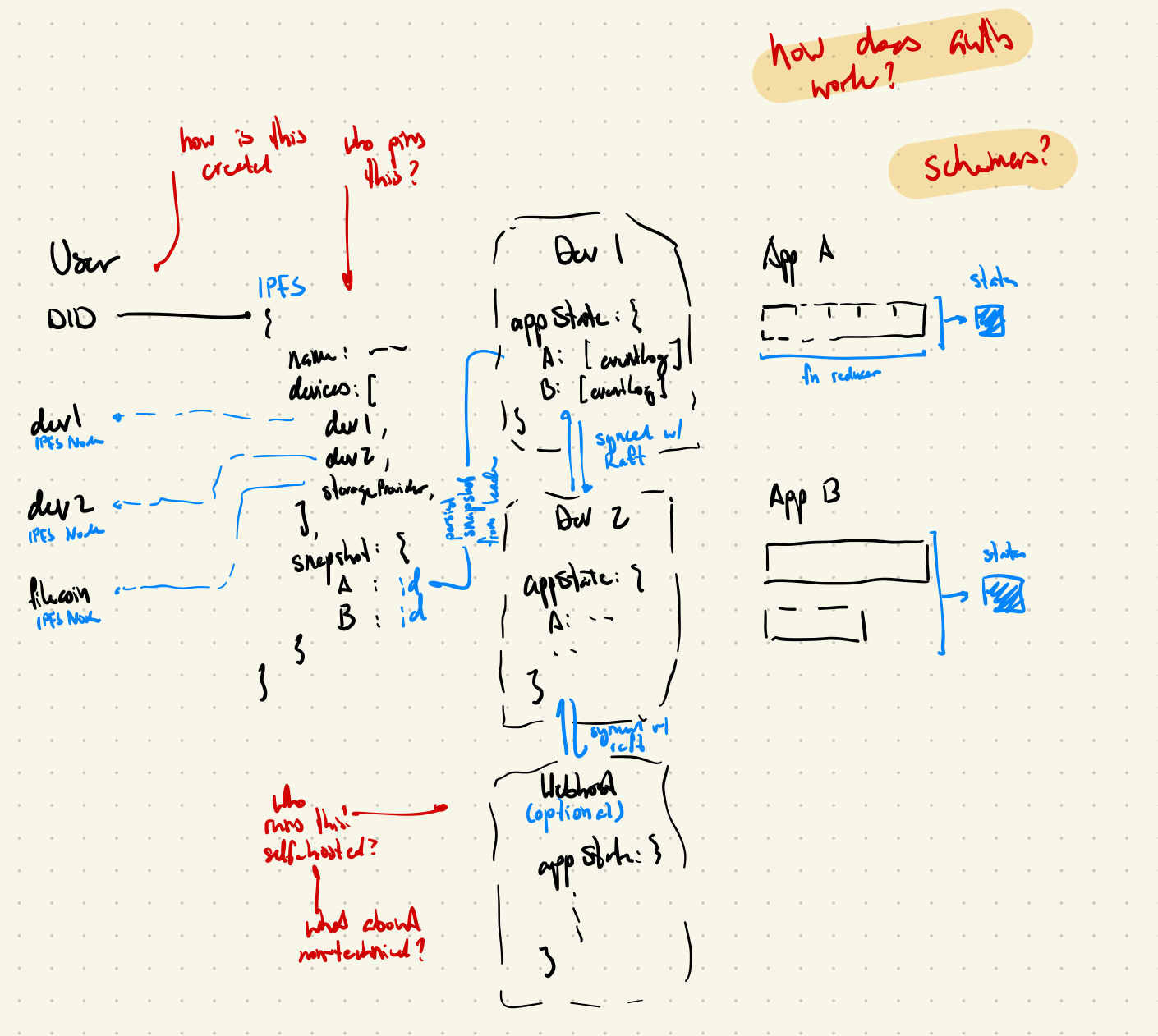
May 2nd
- Mostly reading about Raft consensus algorithm today and understanding how it works
- Always wondered how these consensus algorithms deal with bad actors — turn out they don’t! That’s where BFT comes in
- Seems to be promising for replicating between trusted peers (potentially applicable)
- Starting a very minimal stripped down implementation of Raft in Rust I am nicknaming
miniraft. Code here (but will most likely be private until it is done).
May 1st
- Settling back into home, general research reading + writing the proposal
- Read various papers
- Learned about the basic premise of SSI