Unix philosophy: expect the output of every program to become the input to another, as yet unknown, program.
See also: computer architecture
Manual Pages
The number in parentheses shown after Unix command names in manpages refers to which section it falls under. The main sections are:
- Section 1: user commands and tools, for example, file manipulation tools, shells, compilers, web browsers, file and image viewers and editors, and so on.
- Section 2: Syscalls.
- Section 3: all library functions excluding the library functions described in Section 2. Many of the functions described in the section are part of the Standard C Library (libc).
- Section 4: special files (devices,
null, etc.). - Section 5: file formats and file systems.
- Section 6: games and ‘funny little programs’.
- Section 7: misc.
- Section 8: administration and privileged commands.
Processes
A process is a program in execution in memory or in other words, an instance of a program in memory. Any program executed creates a process.
The proc filesystem is a pseudo-filesystem which provides an interface to kernel data structures. It is commonly mounted at
/proc.
/proc/:pidsubdirectories- Each one of these subdirectories contains files and subdirectories exposing information about the process with the corresponding process ID.
/proc/:pid/task/:tidcontains corresponding information about each of the threads in the process, wheretidis the kernel thread ID of the thread./proc/:pid/nsis a subdirectory containing one entry for each namespace that supports being manipulated by setns(2)./proc/:pid/oom_score_adjis a file used to adjust the score used to select which process should be killed in an out-of-memory (OOM) situation. A positive score increases the likelihood of this process being killed by the OOM-killer; a negative score decreases the likelihood.
/proc/self- When a process accesses this magic symbolic link, it resolves to the process’s own
/proc/piddirectory.
- When a process accesses this magic symbolic link, it resolves to the process’s own
See also: Permissions
PID1 Zombies
Zombie processes: processes that have terminated but have not (yet) been waited for by their parent processes.
Unix processes are ordered in a tree. Each process can spawn child processes, and each process has a parent except for the top-most process.
This top-most process is the init process. It is started by the kernel when you boot your system. This init process is responsible for starting the rest of the system, such as starting the SSH daemon, starting the Docker daemon, starting Apache/Nginx, starting your GUI desktop environment, etc. Each of them may in turn spawn further child processes.
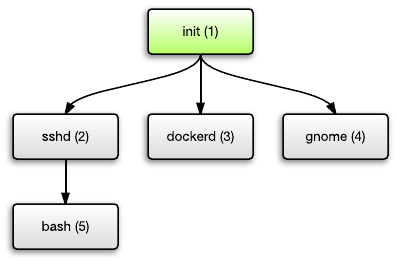
If a process terminates, it turns into a “zombie process” which Unix still keeps some minimal set of information about (PID, termination status, resource usage information). In Unix, parent processes must explicitly ‘wait’ for child processes to terminate.
The action of calling waitpid() on a child process in order to eliminate its zombie, is called “reaping”.
If a parent process is killed, the children are ‘orphaned’ (have no parent process). PID1’s job has a special task to adopt these orphaned processes and becomes the parent. Thus, the operating system expects the init process to reap adopted children too.
Signals
Signals are standardized messages sent to a running program to trigger specific behavior, such as quitting or error handling.
- SIGTERM can also be referred as a soft kill because the process that receives the SIGTERM signal may choose to ignore it. Allows the process to cleanup, etc.
- SIGKILL is used for immediate termination of a process. This signal cannot be ignored or blocked. SIGKILL cannot be trapped, so there is no way for processes to terminate cleanly. Suppose that the app you’re running is busy writing a file; the file could get corrupted if the app is terminated uncleanly in the middle of a write. Unclean terminations are bad. It’s almost like pulling the power plug from your server.
Unix Domain Sockets
A Unix domain socket aka UDS or IPC socket (inter-process communication socket) is a data communications endpoint for exchanging data between processes executing on the same host operating system. It is also referred to by its address family AF_UNIX.
Valid socket types in the UNIX domain are:
- SOCK_STREAM (compare to TCP) – for a stream-oriented socket
- SOCK_DGRAM (compare to UDP) – for a datagram-oriented socket that preserves message boundaries (as on most UNIX implementations, UNIX domain datagram sockets are always reliable and don’t reorder datagrams)
- SOCK_SEQPACKET (compare to SCTP) – for a sequenced-packet socket that is connection-oriented, preserves message boundaries, and delivers messages in the order that they were sent
Importantly, UDS can transfer not only data but also file descriptors (!!!) which means you can transmute a lot of things between processes.
Pseudo-devices
Common UNIX psuedo-devices:
/dev/null– accepts and discards all input written to it; provides an end-of-file indication when read from/dev/zero– accepts and discards all input written to it; produces a continuous stream of null characters as output when read from/dev/full– produces a continuous stream of null characters (zero-value bytes) as output when read from, and generates an ENOSPC error when attempting to write to it/dev/random– produces bytes generated by the kernel’s cryptographically secure pseudorandom number generator. Its exact behavior varies by implementation