Towards real-time read-write hypertext
TLDR; a simpler and more understandable form of CvRDT that relies on a strong notion of happens-before causal relationships and unique identifiers.
- The objective is to automate information dissemination the way hyperlink automated associations and search engines automated search.
- Speculatively, as people become more and more densely connected, they are more and more aware of each other’s details. As a consequence, communications naturally gravitate to compact and speedy update-only forms
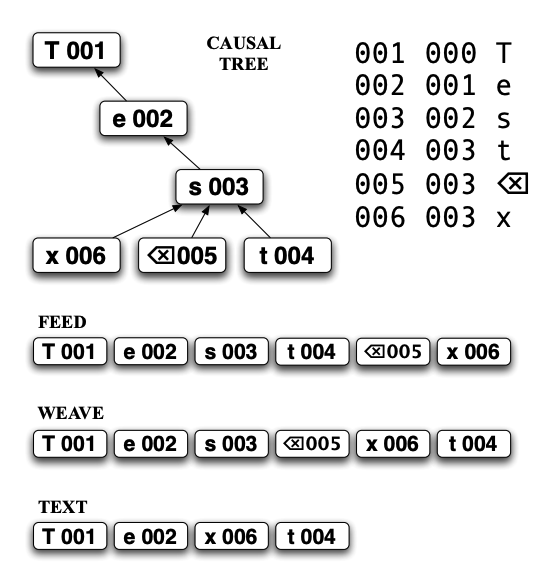
- Causal Trees
- A tree of atoms. Atoms are triples of
(id, causing_id, letter).- Any set of changes can be represented as a set of atom removals and insertions.
- Atom removals are represented by a special “backspace” atom
idis generated in the form of a owner UUID and a Lamport timestamp
- An atom’s
idis always greater than itscausing_id. This defines a partial order- Thus, the tree is a causality tree where each causing atom acts as a parent to its caused atoms
- Atoms are stored in append-only causality feeds. Every feed complies with that order: the causing atom always precedes any of its caused atoms
- Inserts happen directly to the right of its
causing_id(or parent) - A yarn is a full contiguous sequence of operations at a node
- A tree of atoms. Atoms are triples of
- Merging feeds: sort by
id- This is actually called a weave, which contains every piece of the file to ever exist as well as all the special characters (e.g. backspace)
- Note that backspace only marks an atom as inactive, it is never actually removed
- This “backspace” atom has high priority so always hugs its parent in the resulting weave
- Recovering the plaintext version of the weave is constructed by removing inactive atoms from the weave.
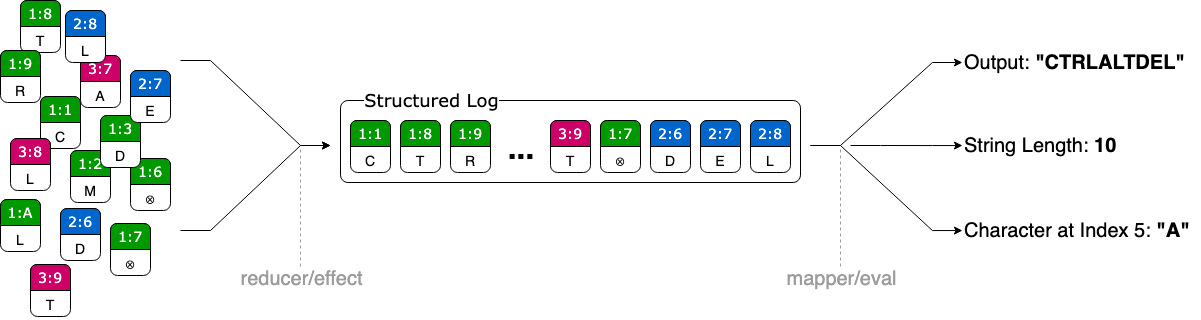
Anyone writing something based on causal trees only needs to define two functions:
- Reducers: inserts arbitrary atoms into an ordered log
- Mapper: traverses the structured log to arrive at a state