Provides causal consistency as well as strong eventual consistency: over time, all actors converge to same state without data loss but there is no guarantee of exact same state across actors at any given moment (not ACID).
Note: In general, maintaining global invariants (e.g. shapes such as a tree or a DAG), cannot be done by a CRDT. Global invariant cannot be determined locally; maintaining it requires synchronisation.
CRDTs should always strive to preserve user intent.
Two main families of CRDTs are operation-based and state-based CRDTs. They have their trade offs
- Operation-based
- generally smaller messages
- requires causally-ordered delivery for messages
- can be more complex because it requires reasoning about history
- State-based
- can tolerate message loss/duplication
- requires best-effort broadcast delivery for messages
See example implementations here: CRDT Implementations
I prefer CRDTs over OT whenever possible because it is just so much easier to grok for the average engineer. The framework tells you clearly what you’d need to do to make async editing actually work (make the update operation commutative), why that’s so difficult (delete operations lose state) and how to make your life much easier (retain delete state and do some form of GC after the fact).
Operation-based
Sometimes also called commutative replicated data types (CmRDT)
Replication requires one of the following assumptions:
- all concurrent operations to commute given causal ordering (most common)
- all operations to commute given no ordering
- all operations to commute and be idempotent if message duplication can occur
History is kept through the notion of a causal history
- Initially,
- After executing the 2nd (downstream) phase of operation ,
State-based
Sometimes also called convergent replicated data types (CvRDT)
Can broadcast the values of the state using best-effort broadcast and then merging using a defined merge operator .
The merge operator must be:
- Commutative:
- Associative:
- Idempotent:
History is kept through the notion of a causal history
- Initially,
- After an update operation ,
- After merging states , , The happens-before relation is then defined as
Delta-based (hybrid)
Delta-based CRDTs propagate delta-mutators that encode the changes that have been made to a replica since the last communication.
For efficiency, CRDT implementations can ‘hold on’ to outbound events and compact/compress the log by rewriting operations (e.g. turning two add(1) operations into a single add(2) operation)
Strategies for Designing CRDTs
A CRDT can be specified by relying on:
- the full history of updates executed;
- the happens-before relation among updates; and
- an arbitration relation among updates (when necessary)
A query can be specified as a function that uses this information and the value of parameters to compute the result (i.e. goes from the state to a value).
Secure CRDTs
- What does encryption in CRDTs look like? homomorphic encryption for merge operations for example
- https://martin.kleppmann.com/papers/snapdoc-pets19.pdf
- http://www.complang.tuwien.ac.at/kps2015/proceedings/KPS_2015_submission_25.pdf
Fault Tolerance
How can we make CRDTs Byzantine fault-tolerant?
Kleppmann shows that is possible to guarantee the standard CRDT consistency properties even in systems in which arbitrarily many nodes are Byzantine.
CRDTs can become BFT by ensuring eventual delivery and convergence even in the presence of Byzantine nodes.
The main construct here is constructing a hash graph (aka a Merkle-DAG): The graph is essentially the Hasse Diagram of the partial order representing the causality relation among the updates. The ID of an operation is the hash of the update containing that operation. A ‘head’ is just an operation which is not a dependency of another operation.
- This hash graph helps to ensure eventual consistency as two nodes and can exchange the hashes of their currents heads and if they are identical, they can ensure the set of updates they have observed is also identical.
- If the heads of and are mismatched, the nodes can run a graph traversal algorithm to determine which parts of the graph they have in common, and send each other those parts of the graph that the other node is lacking.
See: bft-json-crdt
Undo
Approach inspired by xi-editor. Source
This means that the easy way to implement history, which is to simply roll back to a previous state, does not work. The state that is created by undoing your change, if other people’s changes have come in after it, is a new one, not seen before.
To be able to implement this, we can define changes (steps) in such a way that they can be inverted, producing a new step that represents the change that cancels out the original step.
Each editing operation is assigned an “undo group.” Several edits may be in the same group. For example, if the user types ", then a smart-quote plugin may revise that to ‘“’. If the smart-quote revision is assigned the same undo group (because it is a consequence of the same user action), then a single undo would zorch both edits. Each undo group gets a distributed counter, and the group is considered to be undone when the counter is odd-valued.
Performance
Storage + State Compaction
Practical experience with CRDTs shows that they tend to become inefficient over time, as tombstones accumulate and internal data structures become unbalanced. The compacted portion of the CRDT must retain enough metadata to allow future operations to reference it on an atomic level and order themselves correctly. From the outside, a compacted CRDT must continue to behave exactly the same as a non-compacted CRDT.
However, GC + rebalancing technically requires achieving consensus on nodes in order to do this.
So, as far as I know, we would need a consensus protocol attached to the CRDT in order to get garbage collection / compaction. (#2)
One potential way of overcoming this is to have a small, stable subset of replicas called the core which achieve consensus amongst each other. The other replicas asynchronously reconcile their state with core replicas.
See also: Antimatter
Exploiting good connectivity for stronger consistency
Upgrading network assumption from asynchronous to partially synchronous enables us to potentially define weak operations which only eventually need to be linearized.
Move Operations
Generally a difficult problem because the naive move operation needs to ensure global invariants (a node cannot be concurrently moved to two different places) and we know that under I-Confluence, this is impossible with a CRDT.
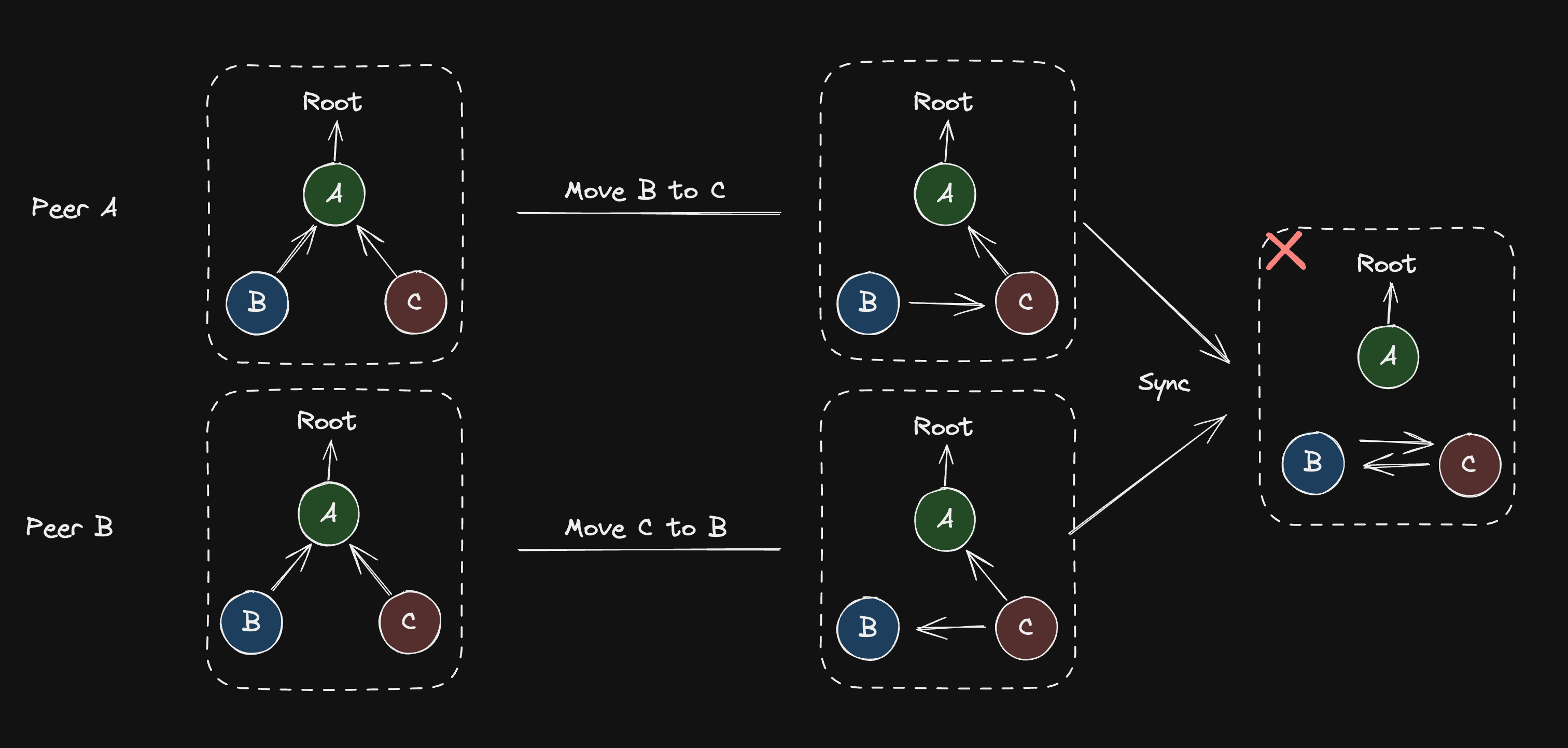 Source from Loro.dev
Source from Loro.dev
Loro solves this by combining the three tree operations (create, delete, move) into a single move operation represented as a 4-tuple (Move t p m c):
-
t: Lamport timestamp -
p: parent node ID -
m: data/metadata -
c: child node ID -
If
cis unique, theMoveoperation creates a childcunderp -
Otherwise, the operation moves
cfrom original parent top -
Deletes are modeled as a move to a special parent
pTRASH
Now that delete is a move, the only remaining problem is about how to introduce and hold global invariants. Loro solves this using undo-replay.
If at any time it receives an operation op that is older than what it knows about, it will undo all operations that are newer than op, apply op, and then replay the undone operations.