Machine Learning
Source: Intro to Reinforcement Learning: The Explore-Exploit Dilemma
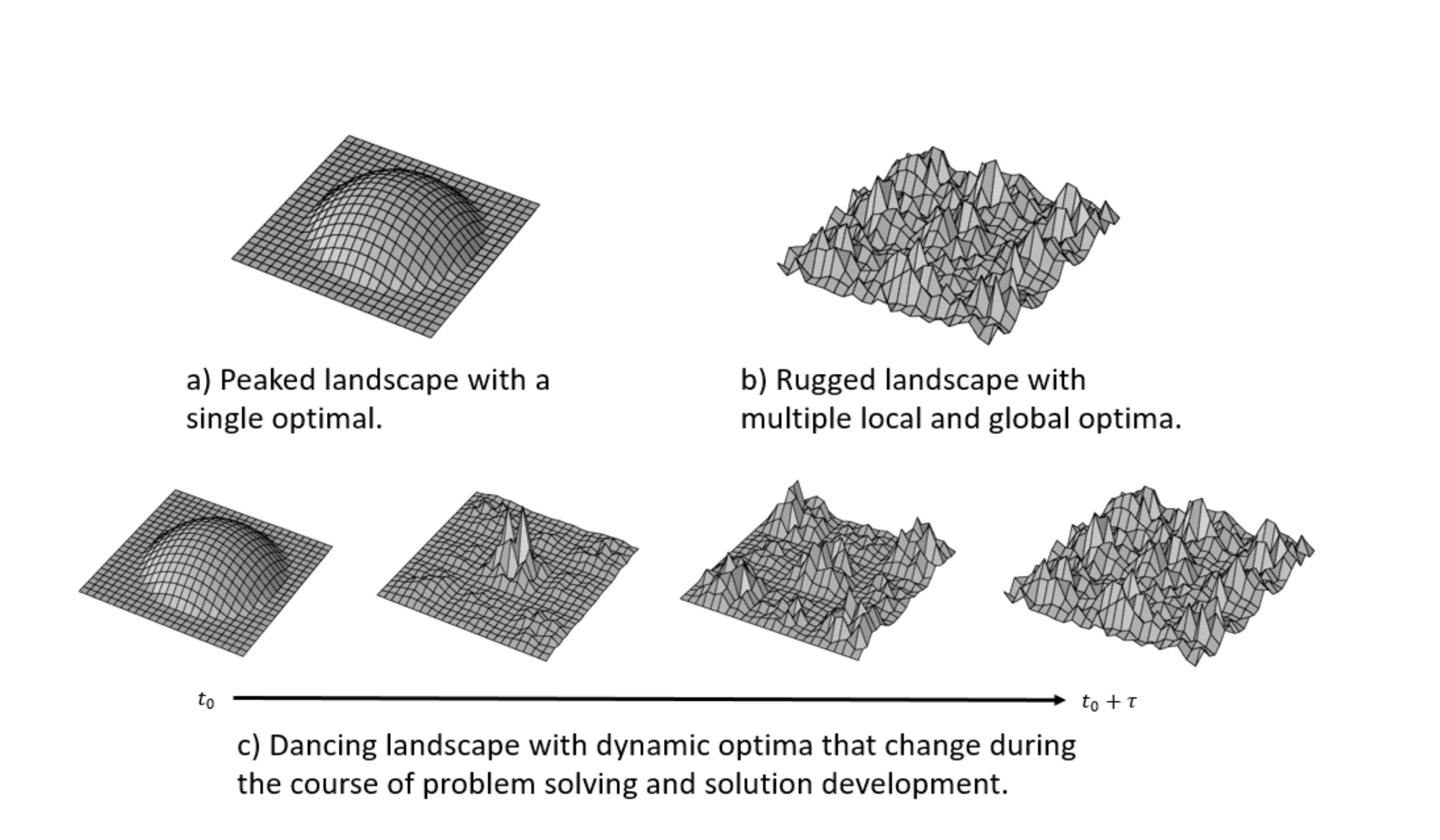
Exploit-explore tradeoff in machine learning is a hill climbing/optimization problem (see: gradient descent).
Always jump to next step up is analogous to greedy search.
Pendulum of life
Source: The Joy of Wasting Time by Samson Zhang
“The ideal is to find an equilibrium point between external pulls and internal pushes, between exploitation (of your current opportunities via external pulls) and exploration (of your actual passions via internal pushes)… the process of finding equilibrium often takes the form of a damped oscillation over time”
However in real life, what this hill climbing problem landscape may look like will erode and grow and change with time.
Regret Minimization Framework
Source: Bezos on the Regret Minimization Framework
Project yourself to age 80 and look back on your life. How do I minimize the regrets that I have? Will you regret abandoning this idea?
When you minimize future regret, you sleep well knowing you’re maximizing fulfilment.
Is a life well-lived one that is fully maximized? What if I just want to live for vibes (which are inherently unoptimizable)?
Multi-armed Bandit
The multi-armed bandit problem models an agent that simultaneously attempts to acquire new knowledge (called “exploration”) and optimize their decisions based on existing knowledge (called “exploitation”). The agent attempts to balance these competing tasks in order to maximize their total value over the period of time considered.
The name comes from imagining a gambler at a row of slot machines (sometimes known as “one-armed bandits”), who has to decide which machines to play, how many times to play each machine and in which order to play them, and whether to continue with the current machine or try a different machine.