At a high-level, we can think of a transformer model as taking an input sequence of tokens of length and predicting the next token at index . They generally excel at sequence-to-sequence modeling tasks.
Most implementations of transformers are autoregressive, meaning that it predicts future values (index to ) from past values (index to ).
Inference
Mainly derived from Brendan Bycroft’s amazing LLM visualization
Embedding
The smallest unit of understanding for a transformer is a token. This is usually a common sequence of characters like ‘at’ or ‘qu’.
The collection of all the tokens the model understands is its vocabulary. The vocabulary maps the token to its index:
- Token A: index 0
- Token B: index 1
- Token C: index 2
This lookup table is usually trained or determined independently of the LMM itself. Most people use statistical methods based on the data to figure out a good lookup table. One common example of this is BPE.
The first step of a transformer is turning the input text into the appropriate index in the vocabulary table.
Then, we use the token index to select the associated column in the token embedding matrix (e.g. the 3rd token index corresponds to the 3rd column of the token embedding matrix). The values of the token embedding matrix are vectors which we call the token embeddings. The token embedding matrix is where is the dimensionality of this embedding.
Then, based on the index of the token in the input, we use it to select an appropriate column of the position embedding matrix. The dimensionality of this is the same as . We need position embeddings because, unlike RNNs and LSTMs which operate sequentially, Transformers operate over the whole input sequence at once so it loses information related to token order.
Why can't we just use a column vector of what index the token is?
A few good criteria for a positional embedding function:
- It should output a unique encoding for each time-step (word’s position in a sentence)
- Distance between any two time-steps should be consistent across sentences with different lengths.
- Our model should generalize to longer sentences without any efforts. Its values should be bounded.
- It must be deterministic.
We try to regularize our weights to ensure they stay close to zero (but not zero exactly!). This would disproportionately distort the embeddings of later tokens! Even if we embed it as a fraction of the total sequence length (so that the position embedding for the first token is a column-vector of and the for the last token), that wouldn’t work either as for different lengths of inputs, we would get different position embeddings for the same token position.
The people who wrote the original Transformer paper “Attention Is All You Need” came up with a very smart way of representing position by using:
- for even dimensions and
- for odd dimensions
The key part for avoiding collisions was the fact that the wavelength changes depending on , the dimension. Even if the positional encoding of the first dimension of position and position are the same (due to periodicity in sinusoidal functions), it is very unlikely that given a reasonably high , we get the same positional embedding for different .
The intuition for this comes from how we represent numbers in binary.
0000000100100011010001010110011110001001101010111100110111101111Bits in different positions have ‘differing rates of change’. The LSB flips every number, the second-LSB flips every other number, etc. and we get a unique encoding of every number. Using discrete values isn’t great for gradient descent so what’s the continuous version of what’s happening here? Sinusoidal functions.
The paper authors also experimented with learned positional embeddings and found similar performance but ultimately chose the sinusoidal version as it meant that the model can extrapolate to sequence lengths outside ones encountered in training.
Token embeddings are learned during training whereas positional encodings can either be fixed or learned. As both embeddings have the same dimensionality, we simply perform an element-wise addition to get the input embedding.
Running this for all of the input tokens gives us the input embedding matrix of size . This corresponds to a column vector for each token.
Conceptual Intuition
We are mapping each token to some coordinates in embedding space so the model can learn and understand the semantics of each token.
Layer Norm
Normalization is an important step in the training of deep neural networks, and it helps improve the stability of the model during training.
We do this for each column of the input embedding matrix separately. The goal is to make the average value in the column equal to 0 and the standard deviation equal to 1. To do this, we find both of these quantities (mean and standard deviation ) for the column and then subtract the average and divide by the standard deviation. Finally, we multiply by a learned weight and a learned bias .
That is, for each where is a column of the input embedding matrix, then we do
We add an additional small to prevent dividing by zero. This produces the layer norm matrix of size .
Transformer Block
As is common in deep learning, it’s hard to say exactly what each of these layers is doing, but we have some general ideas: the earlier layers tend to focus on learning lower-level features and patterns, while the later layers learn to recognize and understand higher-level abstractions and relationships.
In the context of NLP, the lower layers might learn grammar, syntax, and simple word associations, while the higher layers might capture more complex semantic relationships, discourse structures, and context-dependent meaning.
Self-attention
The first step is to produce three vectors for each of the columns from the normalized input embedding matrix. These vectors are the:
- : query vector
- : key vector
- : value vector
is the dimensionality of the // vectors (it’s convention to set where is the number of attention heads). For each of , , and , we have associated learned values for the bias and the weights .
To compute , for example, we do (where are the weights of the query matrix and are the biases of the query matrix). Note that this matrix-vector addition isn’t normally mathematically valid as we are adding a matrix of to a vector of but we treat it as an matrix where each column is the original vector.
We can think of this as each self-attention block as a graph with nodes. Then,
- corresponds roughly to ‘what do I have’
- corresponds roughly to ‘what am I looking for’
- corresponds roughly to ‘what information do I share with others’
We can think of ‘attention’ as some node A asking some node B for information:
- We do to get the self-attention matrix and then divide by .
- Then, we normalize the self-attention matrix with softmax which scales them into probabilities so that each row adds up to a probability of 1.
- We finally multiply the normalized self-attention matrix with to get our attention output of size .
The main goal of self-attention is that each column wants to find relevant information from other columns and extract their values, and does so by comparing its query vector to the keys of those other columns. We also add restriction that it can only look in the past (i.e. causal self-attention).
This self-attention step is run in parallel (multi-headed self-attention). To combine the outputs of the attention heads, we simply stack them on top of each other to get the attention output of size .
Conceptual Intuition
The animal didn't cross the street because it was too tiredWhat does ‘it’ in this sentence refer to? Is it referring to the street or to the animal? When the model is processing the word ‘it’, self-attention allows it to associate ‘it’ with ‘animal’. As the model processes each word (each position in the input sequence), self attention allows it to look at other positions in the input sequence for clues that can help lead to a better encoding for this word.
We can also think of attention as communication in a directed graph of vectors: source from ‘Introduction to Transformers w/ Andrej Karpathy’
Projection
Finally, we perform the projection to get the output of the layer. This is a simple matrix-vector multiplication on a per-column basis, with a bias added.
Instead of passing this output directly to the next phase, we add it element-wise to the input embedding. This process is called the residual connection or residual pathway.
MLP
Like with self-attention, we perform a layer normalization before the vectors enter the MLP.
Each MLP block has
- weights (a matrix)
- bias (a column vector)
- projection weights (a matrix)
- projection bias (a column vector)
Each vector from the layer-normed attention residual then, individually:
- to produce a column vector
- GELU element wise to produce
- to produce a column vector
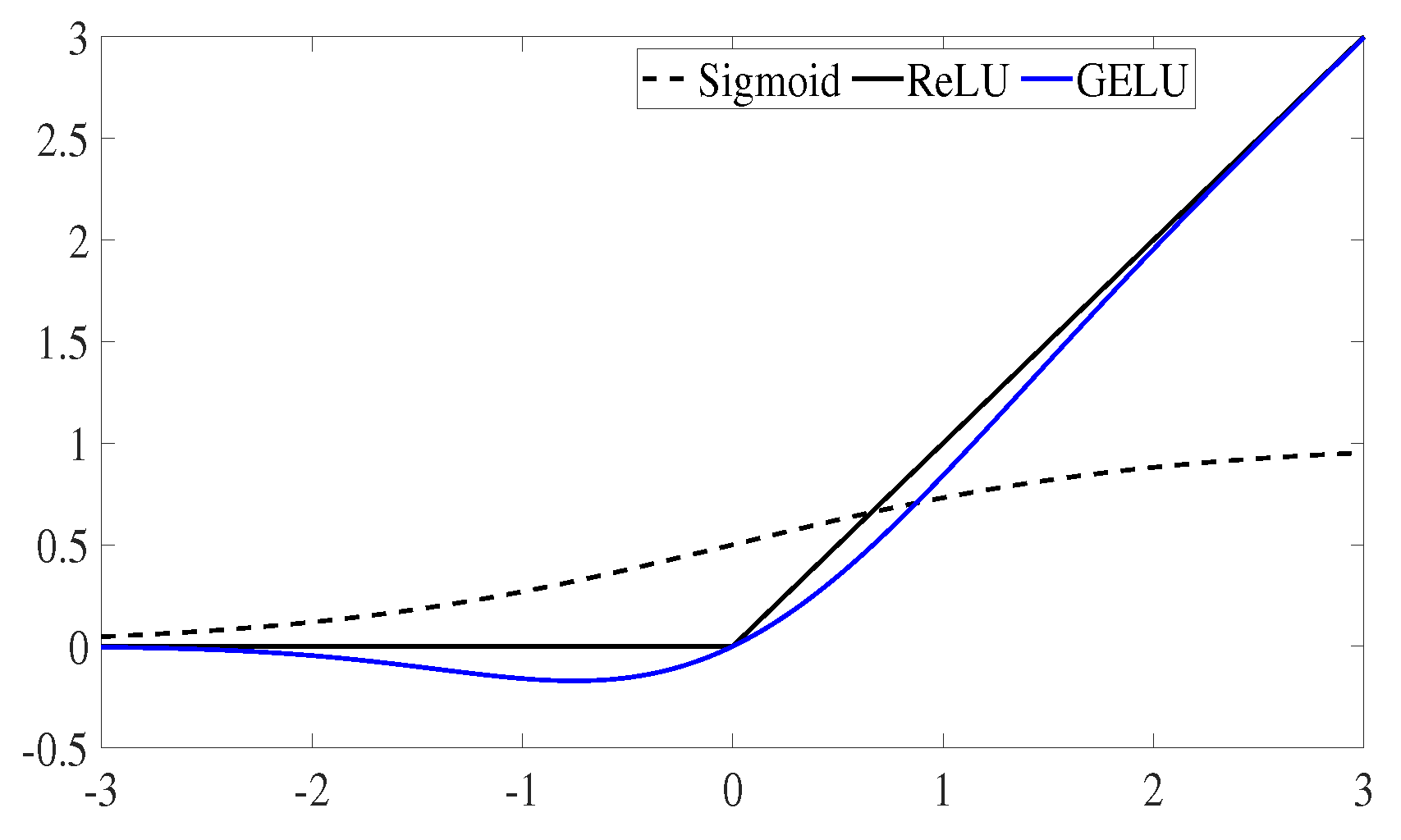 GELU example
GELU example
This is assembled into the MLP result of size . Like in the self-attention + projection section, we add the result of the MLP to its input, element-wise to produce the MLP residual.
This marks the end of the transformer block and the output is ready to be passed to the next block.
Output
Finally, at the end of all the transformer blocks, we perform one final softmax, which helps convert the output into probabilities.
Multi-class Probabilities
See also: multi-class classification
The softmax function allows us to map real numbers to probabilities.
The alternative ‘harder’ version to softmax is the argmax function which simply finds the maximum value, sets it to 1.0, and assigns 0.0 to all other values.
In contrast, the softmax operation serves as a “softer” version of that. Due to the exponentiation involved in softmax, the largest value is emphasized and pushed towards 1.0, while still maintaining a probability distribution over all input values. This allows for a more nuanced representation that captures not only the most likely option but also the relative likelihood of other options.
Probabilistic Classifier
We then take this output block and do a final matrix multiply with another set of learned weights called the language modelling head weights (LM weights) which is a matrix.
This produces the logits of size . The name “logits” comes from “log-odds,” i.e., the logarithm of the odds of each token. Finally, we softmax this again to exponentiate the log-odds to normal odds/probabilities.
Now, for each column, we have a probability the model assigns to each word in the vocabulary. Then, we can ‘decode’ the final probability back into a token. For example if we’ve supplied six tokens into the model, we’ll use the output probabilities of the 6th column.
We do this by “sampling from the distribution.” That is, we randomly choose a token, weighted by its probability. For example, a token with a probability of 0.9 will be chosen 90% of the time.
We can also control the “smoothness” of the distribution by using a temperature parameter. A higher temperature will make the distribution more uniform, and a lower temperature will make it more concentrated on the highest probability tokens.